The following section describes data extraction to a Google Cloud Storage.
Google Cloud Platform (GCP) is a collection of cloud services provided by Google. Google Cloud Platform is available at cloud.google.com. Google Cloud Storage is one of the Google services used for storing data in the Google infrastructure. For more information see Google Cloud Storage Documentation.
Requirements #
- Google account
- Google Cloud Platform (GCP) subscrition (trial version offered)
- Project (“My First Project” is pre-defined)
- Google Cloud Storage (GCS) bucket for data extractions
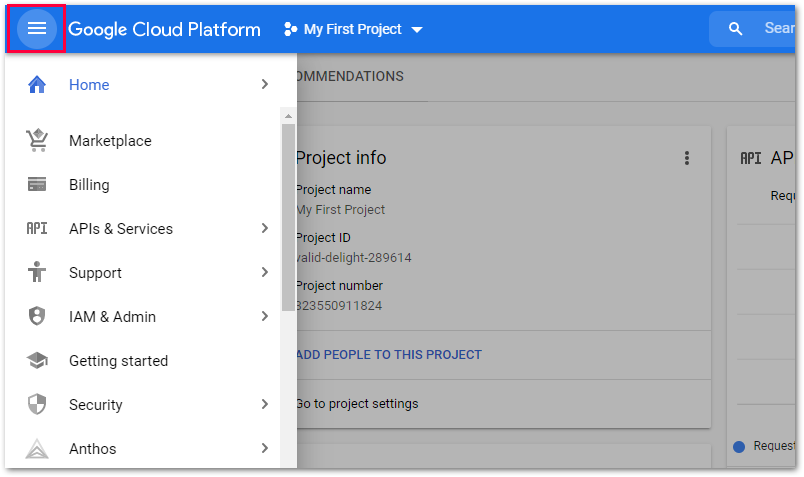
GCP console #
The GCP console allows configuring of all resources and services. To get to the overview dashboard, navigate to the Google Cloud Storage page and click [Console] or [Go to console].
To access all settings and services use the navigation menu on the upper left side.
Connection #
Adding a Destination #
- In the main window of the Designer, navigate to Server > Manage Destinations. The window “Manage Destinations” opens.
- Click [Add] to create a new destination. The window “Destination Details” opens.
- Enter a Name for the destination.
- Select the destination Type from the drop-down menu.
Destination Details #
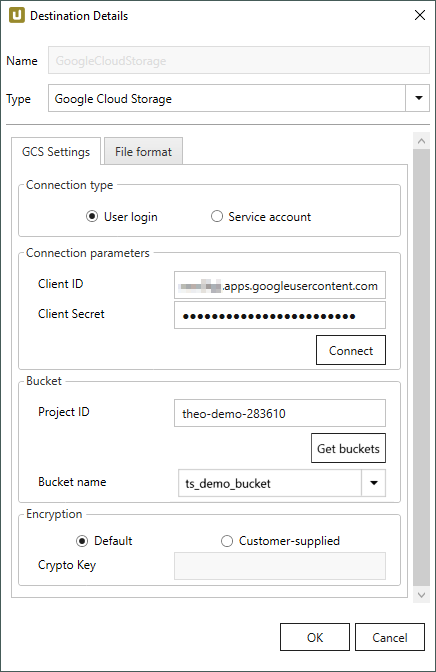
GCS Settings #
Connection Type
Two types of authentication are supported:
- Select User Login to log into Google Cloud Storage using the OAuth client ID authentication, see Connection Parameters.
- Select Service Account to log into Google Cloud Storage using the credentials of a service account for authentication, see Service Acccount File Location.
Connection Parameters
The following settings are only available if the Connection Type is set to User Login.
To enable the OAuth 2.0 protocol, configure an OAuth flow with the required access permissions to Xtract Universal.
For more information, see Knowledge Base Article: Setting Up OAuth 2.0 for the Google Cloud Storage Destination.
Client ID
Client ID created in the OAuth 2.0 setup.
Client Secret
Client Secret created in the OAuth 2.0 setup.
Connect
Processes the previously created OAuth flow to establish a connection with the storage account.
Choose your Google account and grant access to Xtract Universal in all required windows.
Note: If you did not verify the app, a window with the message: “This app isn’t verified” is displayed. Click [Advanced] and [Go to Xtract Universal (unsafe)].
When a connection is successful, an “Authentication succeeded” message is displayed in the browser. In Xtract Universal a “Connection established” message is displayed in a separate window.
Service Acccount File Location
The following settings are only available if the Connection Type is set to Service Account.
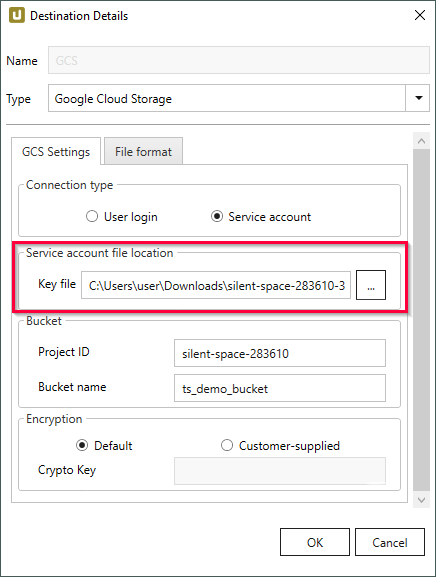
Key File
The service account is identified by a RSA key pair.
When creating the keys, the user receives a service account file from Google containing information about the account.
Provide the location of the service account file.
Make sure that the Xtract Universal service has access to the file.
Bucket
When using OAuth 2.0 authenthication, the “Bucket” subsection can only be filled after a connection to the storage account has been established.
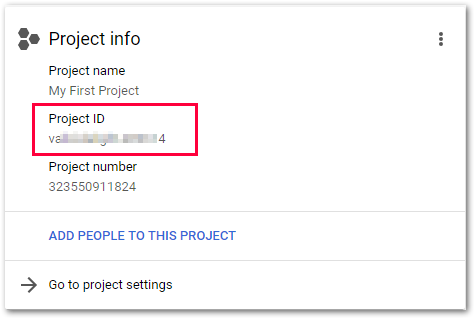
Project ID
The Project ID can be looked up in the GCP dashboard under Project info.
Bucket name
When using OAuth 2.0 authenthication, click [Get buckets] to display available buckets.
A bucket can be created in the navigation menu under Storage > Browser.
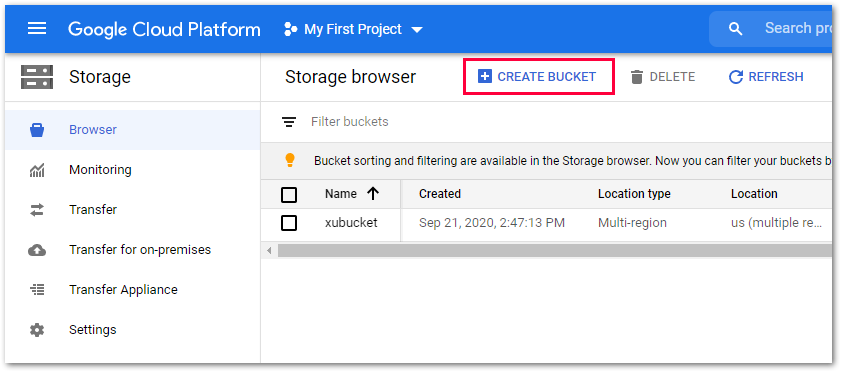
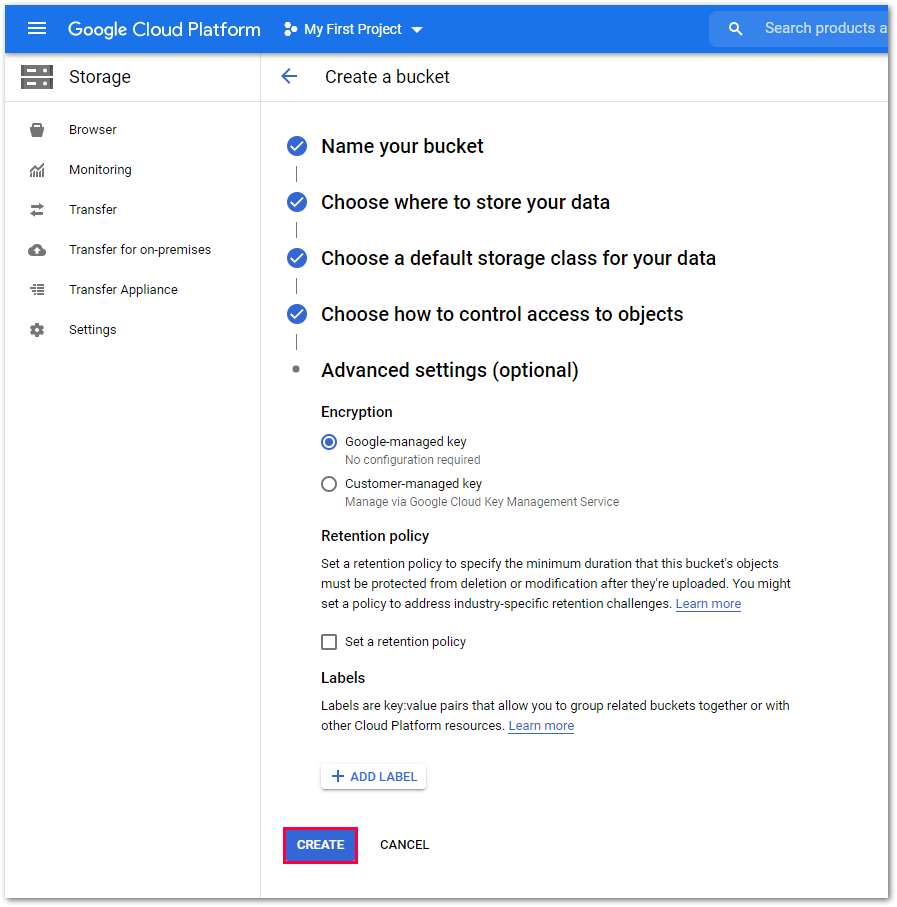
Choose a bucket name, location type and storage class or access control.
Under Advanced Settings (optional) you can select the desired encryption method applied to the bucket. Get more details on encryption on the official Google Help Page.
Encryption
Default
Applies the encryption method specified in your GCS bucket.
Google encrypts all data that is stored on the Google servers by default. In addition you can use the Google Cloud Key Management Service (KMS) to create and apply keys to your buckets.
The KMS can be enabled in the GCP console’s navigation menu under Security > Cryptographic Keys.
Customer-supplied
If you check the Customer-supplied option, you need to provide a valid AES256 Crypto Key (256 bit in length).
The Crypto key is not stored in the GCP and demands the additional effort to be able to to decrypt your data later.
Crypto field
Enter the cryptographic key into the Crypto field if you selected “Customer Supplied” as the encryption method.
File Format #
File type
Select the required file format between “CSV”, “JSON” and “Parquet”.
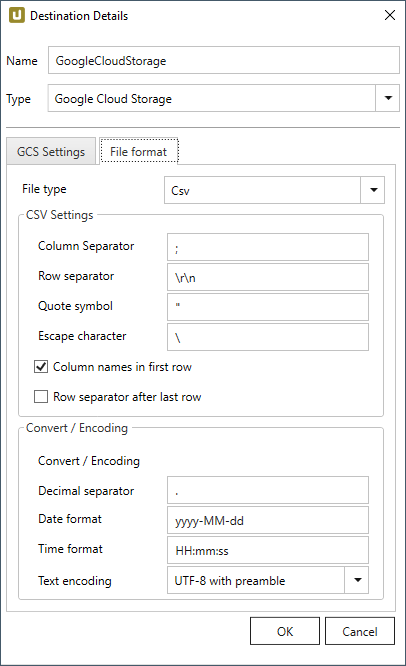
CVS Settings
The settings for file type “CSV” correspond to the Flat File CSV settings.
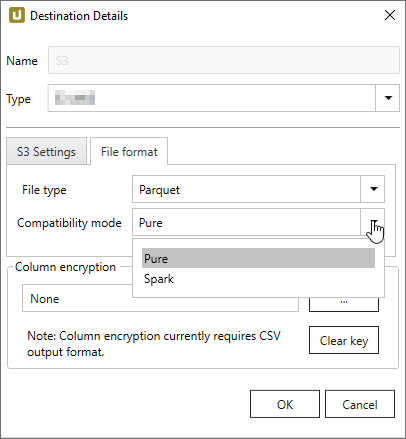
Parquet Settings
The following compatibility modes are available:
- Pure
- Spark
- BigQuery
Spark does not support the data types used in pure mode, so other data types need to be used.
In spark mode special characters and spaces are replaced with an underscore _.
| SAP | Pure / BigQuery | Spark |
|---|---|---|
| INT1 | UINT_8 | INT16 |
| TIMS | TIME_MILLIS | UTF8 |
Connection Retry #
Connection retry is a built-in function of the Google Cloud Storage destination. The retry function is automatically activated.
Connection retry is a functionality that prevents extractions from failing in case of transient connection interruptions to Google Cloud Storage. For more general information about retry strategies in a Google Cloud Storage environment go to the official Google Cloud Help. Xtract universal follows an exponential retry strategy. The selected exponential strategy results in 8 retry attempts and an overall timespan of 140 seconds. If a connection is not established during the timespan of 140 seconds, the extraction fails.
Settings #
Opening the Destination Settings #
- Create or select an existing extraction, see Getting Started with Xtract Universal.
- Click [Destination]. The window “Destination Settings” opens.
The following settings can be defined for the destination:
Destination Settings #
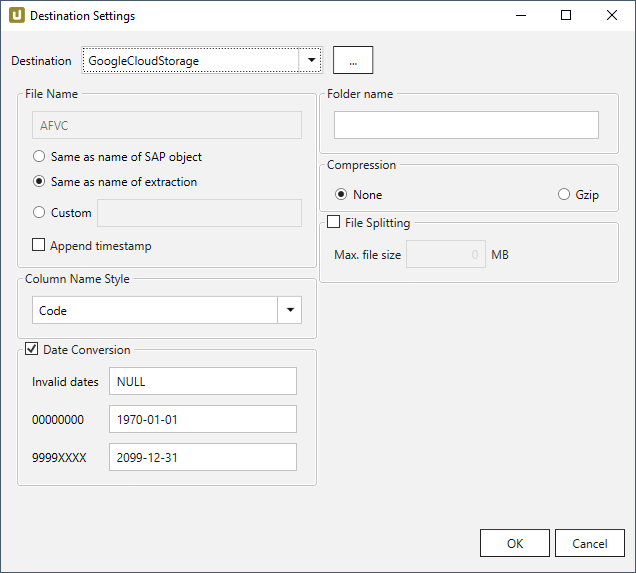
File Name #
File Name determines the name of the target table. You have the following options:
- Same as name of SAP object: Copy the name of the SAP object
- Same as name of extraction: Adopt name of extraction
- Custom: Define a name of your choice
- Append timestamp: Add the timestamp in the UTC format (_YYYY_MM_DD_hh_mm_ss_fff) to the file name of the extraction
Note: If the name of an object does not begin with a letter, it will be prefixed with an ‘x’, e.g. an object by the name _namespace_tabname.csv will be renamed x_namespace_tabname.csv when uploaded to the destination.
This is to ensure that all uploaded objects are compatible with Azure Data Factory, Hadoop and Spark, which require object names to begin with a letter or give special meaning to objects whose names start with certain non-alphabetic characters.
Using Script Expressions as Dynamic File Names
Script expressions can be used to generate a dynamic file name. This allows generating file names that are composed of an extraction’s properties, e.g. extraction name, SAP source object. This scenario supports script expressions based on .NET and the following XU-specific custom script expressions:
| Input | Description |
|---|---|
#{Source.Name}# |
Name of the extraction’s SAP source. |
#{Extraction.ExtractionName}# |
Name of the extraction. If the extraction is part of an extraction group, enter the name of the extraction group before the name of the extraction. Separate groups with a ‘,’, e.g, Tables,KNA1, S4HANA,Tables,KNA1. |
#{Extraction.Type}# |
Extraction type (Table, ODP, BAPI, etc.). |
#{Extraction.SapObjectName}# |
Name of the SAP object the extraction is extracting data from. |
#{Extraction.Timestamp}# |
Timestamp of the extraction. |
#{Extraction.SapObjectName.TrimStart("/".ToCharArray())}# |
Removes the first slash ‘/’ of an SAP object. Example: /BIO/TMATERIAL to BIO/TMATERIAL - prevents creating an empty folder in a file path. |
#{Extraction.SapObjectName.Replace('/', '_')}# |
Replaces all slashes ‘/’ of an SAP object. Example /BIO/TMATERIAL to _BIO_TMATERIAL - prevents splitting the SAP object name by folders in a file path. |
#{Extraction.Context}# |
Only for ODP extractions: returns the context of the ODP object (SAPI, ABAP_CDS, etc). |
#{Extraction.Fields["[NameSelectionFiels]"].Selections[0].Value}# |
Only for ODP extractions: returns the input value of a defined selection / filter. |
#{Odp.UpdateMode}# |
Only for ODP extractions: returns the update mode (Delta, Full, Repeat) of the extraction. |
#{TableExtraction.WhereClause}# |
Only for Table extractions: returns the WHERE clause of the extraction. |
Column Name Style #
Defines the style of the column name. Following options are available:
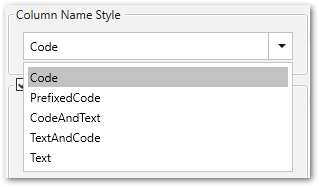
- Code: The SAP technical column name is used as column name in the destination e.g., MAKTX.
- PrefixedCode: The SAP technical column name is prefixed by SAP object name and the tilde character e.g., MAKT~MAKTX
- CodeAndText: The SAP technical column name and the SAP description separated by an underscore are used as column name in the destination e.g., MAKTX_Material Description (Short Text).
- TextAndCode: The SAP description and the SAP technical column name description separated by an underscore are used as column name in the destination e.g., Material Description (Short Text)_MAKTX.
- Text: The SAP description is used as column name in the destination e.g., Material Description (Short Text).
Date conversion #
Convert date strings
Converts the character-type SAP date (YYYYMMDD, e.g., 19900101) to a special date format (YYYY-MM-DD, e.g., 1990-01-01). Target data uses a real date data-type and not the string data-type to store dates.
Convert invalid dates to
If an SAP date cannot be converted to a valid date format, the invalid date is converted to the entered value. NULL is supported as a value.
When converting the SAP date the two special cases 00000000 and 9999XXXX are checked at first.
Convert 00000000 to
Converts the SAP date 00000000 to the entered value.
Convert 9999XXXX to
Converts the SAP date 9999XXXX to the entered value.
Folder name #
To write extraction data to a location within a specific folder in a Google Cloud Storage bucket, enter a folder name without slashes.
Subfolders are supported and can be defined using the following syntax:
[folder]/[subfolder_1]/[subfolder_2]/…
Using Script Expressions as Dynamic Folder Paths
Script expressions can be used to generate a dynamic folder path. This allows generating folder paths that are composed of an extraction’s properties, e.g., extraction name, SAP source object. The described scenario supports script expressions based on .NET and the following XU-specific custom script expressions:
| Input | Description |
|---|---|
#{Source.Name}# |
Name of the extraction’s SAP source. |
#{Extraction.ExtractionName}# |
Name of the extraction. If the extraction is part of an extraction group, enter the name of the extraction group before the name of the extraction. Separate groups with a ‘,’, e.g, Tables,KNA1, S4HANA,Tables,KNA1. |
#{Extraction.Type}# |
Extraction type (Table, ODP, BAPI, etc.). |
#{Extraction.SapObjectName}# |
Name of the SAP object the extraction is extracting data from. |
#{Extraction.Timestamp}# |
Timestamp of the extraction. |
#{Extraction.SapObjectName.TrimStart("/".ToCharArray())}# |
Removes the first slash ‘/’ of an SAP object. Example: /BIO/TMATERIAL to BIO/TMATERIAL - prevents creating an empty folder in a file path. |
#{Extraction.SapObjectName.Replace('/', '_')}# |
Replaces all slashes ‘/’ of an SAP object. Example: /BIO/TMATERIAL to _BIO_TMATERIAL - prevents splitting the SAP object name by folders in a file path. |
#{Extraction.Context}# |
Only for ODP extractions: returns the context of the ODP object (SAPI, ABAP_CDS, etc). |
#{Extraction.Fields["[NameSelectionFields]"].Selections[0].Value}# |
Only for ODP extractions: returns the input value of a defined selection / filter. |
#{Odp.UpdateMode}# |
Only for ODP extractions: returns the update mode (Delta, Full, Repeat) of the extraction. |
#{TableExtraction.WhereClause}# |
Only for Table extractions: returns the WHERE clause of the extraction. |
#{Extraction.Fields["[0D_NW_CODE]"].Selections[0].Value}# |
Only for BWCube extractions (MDX mode): returns the input value of a defined selection. |
#{Extraction.Fields["[0D_NW_CHANN]"].RangeSelections[0].LowerValue}# |
Only for BWCube extractions (MDX mode): returns the lower input value of a defined selection range. |
#{Extraction.Fields["[0D_NW_CHANN]"].RangeSelections[0].UpperValue}# |
Only for BWCube extractions (MDX mode): returns the upper input value of a defined selection range. |
#{Extraction.Fields["0D_NW_CODE"].Selections[0].Value}# |
Only for BWCube extractions (BICS mode): returns the input value of a defined selection. |
#{Extraction.Fields["0D_NW_CHANN"].RangeSelections[0].LowerValue}# |
Only for BWCube extractions (BICS mode): returns the lower input value of a defined selection range. |
#{Extraction.Fields["0D_NW_CHANN"].RangeSelections[0].UpperValue}# |
Only for BWCube extractions (BICS mode): returns the upper input value of a defined selection range. |
Compression #
None
The data is transferred uncompressed and stored as a csv file.
gzip
The data is transferred compressed and stored as a gz file.
Note: Compression is only available for the csv file format, see Connection: File Format.
File Splitting #
File Splitting
Writes extraction data of a single extraction to multiple files in the cloud.
Each filename is appended by _part[nnn].
Max. file size
The value set in Max. file size determines the maximum size of each stored file.
Note: The option Max. file size does not apply to gzip files. The size of a gzipped file cannot be determined in advance.