The following section describes the loading of the SAP extraction data to a Microsoft SQL Server Database or a Microsoft Azure SQL Database destination.
Requirements #
No driver installation is required since the ADO .NET driver for SQL Server is delivered and installed as a part of the .NET framework.
Connection #
Adding a Destination #
- In the main window of the Designer, navigate to Server > Manage Destinations. The window “Manage Destinations” opens.
- Click [Add] to create a new destination. The window “Destination Details” opens.
- Enter a Name for the destination.
- Select the destination Type from the drop-down menu.
Destination Details #
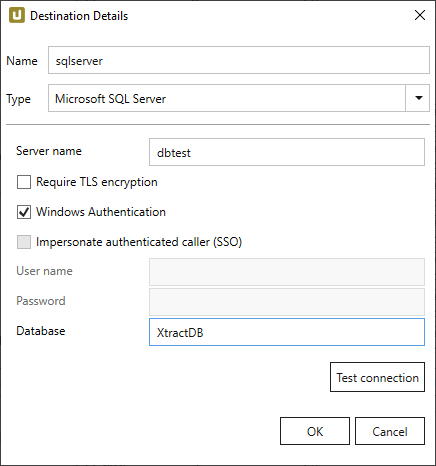
Server Name
Specifies the host address of the SQL Server. Please note the following syntax:
| syntax | e.g. |
|---|---|
| [ServerName] | dbtest |
| [ServerName],[Port] | dbtest,1433 |
| [ServerName].[Domain],[Port] | dbtest.theobald.software,1433 |
It is only necessary to specify the port if it has been edited outside the SQL standard.
Require TLS encryption
Client-side enforcement for using TLS encrpytion. Adds the following parameters to the connection string:
- Encrypt = On
- TrustServerCertificate = Off
For further information, please see Enable Encrypted Connections to the Database Engine
Windows Authentication
Uses the service account, under which the XU service is running, for authentication against SQL Server.
Note: To successfully connect to the database using Windows authentication, make sure to run the XU service under a Windows AD user with access to the database.
Impersonate authenticated caller
Uses the Windows AD user, executing the extraction, for authentication against SQL Server using Kerberos authentication.
For using this functionality a similar configuration as for Kerberos Single Sign On against SAP is required.
User Name
SQL Server authentication - user name
Password
SQL Server authentication - password
Database Name
Defines the name of the SQL Server database.
Test Connection
Checks the database connection.
Settings #
Opening the Destination Settings #
- Create or select an existing extraction, see Getting Started with Xtract Universal.
- Click [Destination]. The window “Destination Settings” opens.
The following settings can be defined for the destination:
Destination Settings #
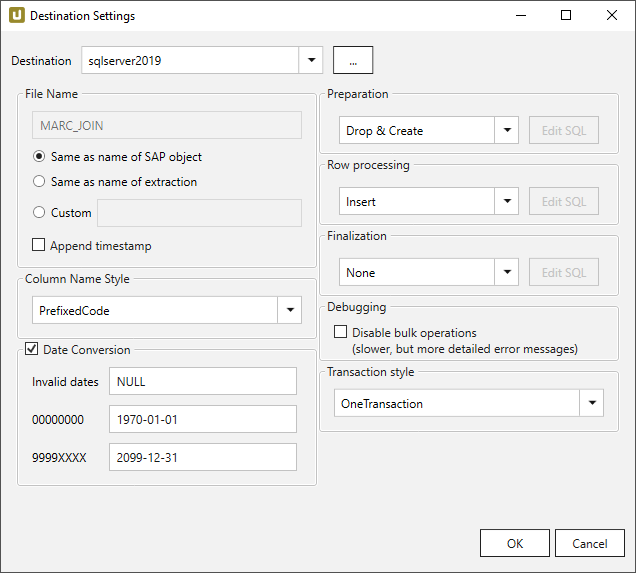
File Name #
File Name determines the name of the target table. You have the following options:
- Same as name of SAP object: Copy the name of the SAP object
- Same as name of extraction: Adopt name of extraction
- Custom: Define a name of your choice
- Append timestamp: Add the timestamp in the UTC format (_YYYY_MM_DD_hh_mm_ss_fff) to the file name of the extraction
Using Script Expressions as Dynamic File Names
Script expressions can be used to generate a dynamic file name. This allows generating file names that are composed of an extraction’s properties, e.g. extraction name, SAP source object. This scenario supports script expressions based on .NET and the following XU-specific custom script expressions:
| Input | Description |
|---|---|
#{Source.Name}# |
Name of the extraction’s SAP source. |
#{Extraction.ExtractionName}# |
Name of the extraction. If the extraction is part of an extraction group, enter the name of the extraction group before the name of the extraction. Separate groups with a ‘,’, e.g, Tables,KNA1, S4HANA,Tables,KNA1. |
#{Extraction.Type}# |
Extraction type (Table, ODP, BAPI, etc.). |
#{Extraction.SapObjectName}# |
Name of the SAP object the extraction is extracting data from. |
#{Extraction.Timestamp}# |
Timestamp of the extraction. |
#{Extraction.SapObjectName.TrimStart("/".ToCharArray())}# |
Removes the first slash ‘/’ of an SAP object. Example: /BIO/TMATERIAL to BIO/TMATERIAL - prevents creating an empty folder in a file path. |
#{Extraction.SapObjectName.Replace('/', '_')}# |
Replaces all slashes ‘/’ of an SAP object. Example /BIO/TMATERIAL to _BIO_TMATERIAL - prevents splitting the SAP object name by folders in a file path. |
#{Extraction.Context}# |
Only for ODP extractions: returns the context of the ODP object (SAPI, ABAP_CDS, etc). |
#{Extraction.Fields["[NameSelectionFiels]"].Selections[0].Value}# |
Only for ODP extractions: returns the input value of a defined selection / filter. |
#{Odp.UpdateMode}# |
Only for ODP extractions: returns the update mode (Delta, Full, Repeat) of the extraction. |
#{TableExtraction.WhereClause}# |
Only for Table extractions: returns the WHERE clause of the extraction. |
Column Name Style #
Defines the style of the column name. Following options are available:
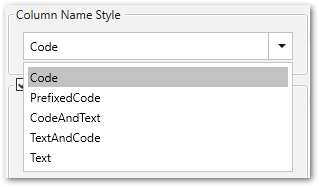
- Code: The SAP technical column name is used as column name in the destination e.g., MAKTX.
- PrefixedCode: The SAP technical column name is prefixed by SAP object name and the tilde character e.g., MAKT~MAKTX
- CodeAndText: The SAP technical column name and the SAP description separated by an underscore are used as column name in the destination e.g., MAKTX_Material Description (Short Text).
- TextAndCode: The SAP description and the SAP technical column name description separated by an underscore are used as column name in the destination e.g., Material Description (Short Text)_MAKTX.
- Text: The SAP description is used as column name in the destination e.g., Material Description (Short Text).
Date conversion #
Convert date strings
Converts the character-type SAP date (YYYYMMDD, e.g., 19900101) to a special date format (YYYY-MM-DD, e.g., 1990-01-01). Target data uses a real date data-type and not the string data-type to store dates.
Convert invalid dates to
If an SAP date cannot be converted to a valid date format, the invalid date is converted to the entered value. NULL is supported as a value.
When converting the SAP date the two special cases 00000000 and 9999XXXX are checked at first.
Convert 00000000 to
Converts the SAP date 00000000 to the entered value.
Convert 9999XXXX to
Converts the SAP date 9999XXXX to the entered value.
Preparation - SQL Commands #
Defines the action on the target database before the data is inserted into the target table.
- Drop & Create: Remove table if available and create new table (default).
- Truncate Or Create: Empty table if available, otherwise create.
- Create If Not Exists: Create table if not available.
- Prepare Merge: Prepares the merge process and creates e.g. a temporary staging table. See merging for more details.
- None: no action
- Custom SQL: Here you can define your own script. See the Custom SQL section below.
If you only want to create the table in the first step and do not want to insert any data, you have two options:
- Copy the SQL statement and execute it directly on the target data database.
- Select the None option for Row Processing and execute the extraction.
Once the table is created, it is up to you to change the table definition, by, for example, creating corresponding key fields and indexes or additional fields.
Row Processing - SQL Commands #
Defines how the data is inserted into the target table.
- Insert: Insert records (default).
- Fill merge staging table: Insert records into the staging table.
- None: no action.
- Custom SQL: Here you can define your own script. See the Custom SQL section below.
- Merge (deprecated): This option is obsolete. Please use the Fill merge staging table option and check the About Merging section.
Finalization - SQL Commands #
Defines the action on the target database after the data has been successfully inserted into the target table.
- Finalize Merge: Closes the merge process and deletes the temporary staging table, for example.
- None: no action (default).
- Custom SQL: Here you can define your own script. See the Custom SQL section below.
About Merging
Merging ensures delta processing: new records are inserted into the database and / or existing records are updated. See section merging data.
Custom SQL #
Custom SQL option allows creating user-defined SQL or script expressions. Existing SQL commands can be used as templates:
- Within subsection e.g., Preparation select the Custom SQL (1) option from the drop-down list.
- Click [Edit SQL]. The dialogue “Edit SQL” opens.
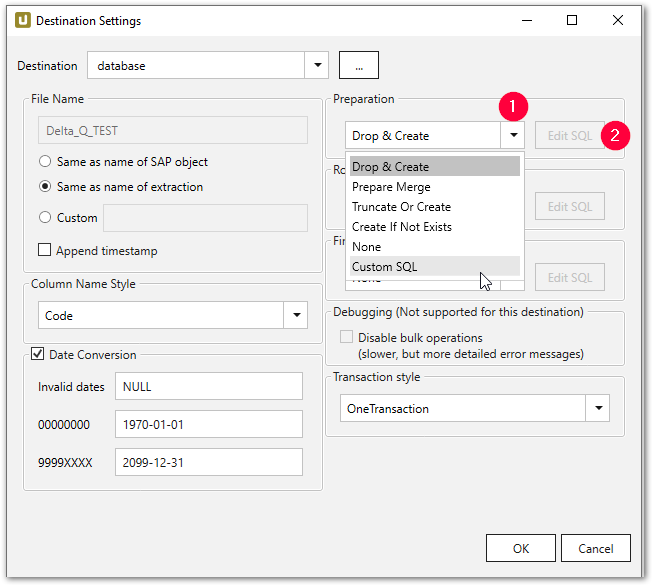
- Navigate to the drop-down menu and select an existing command (3).
- Click [Generate Statement]. A new statement is generated.
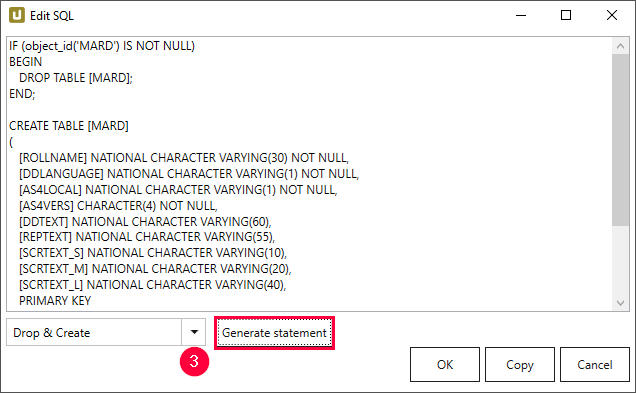
- Click [Copy] to copy the statement to the clipboard.
- Click [OK] to confirm.
Check out the Microsoft SQL Server example for details on predefined expressions.
Note: The custom SQL code is used for SQL Server destinations. A syntactic adaptation of the code is necessary to use the custom SQL code for other database destinations.
Templates
You can write your user-defined SQL expressions and adapt the loading of the data to your needs.
You can additionally execute stored procedures that exist in the database.
To do so, use the SQL templates provided in the following phases:
- Preparation (e.g., Drop & Create or Create if Not Exists)
- Row Processing (e.g., Insert or Merge)
- Finalization
Using Script Expressions
You can use script expressions for the Custom SQL commands.
The following XU-specific custom script expressions are supported:
| Input | Description |
|---|---|
#{Extraction.TableName }# |
Name of the database table extracted data is written to |
#{Extraction.RowsCount }# |
Count of the extracted rows |
#{Extraction.RunState}# |
Status of the extraction (Running, FinishedNoErrors, FinishedErrors) |
#{(int)Extraction.RunState}# |
Status of the extraction as number (2 = Running, 3 = FinishedNoErrors, 4 = FinishedErrors) |
#{Extraction.Timestamp}# |
Timestamp of the extraction |
For more information on script expression, see Script Expressions.
Example SQL script
#{
iif
(
ExistsTable("MAKT"),
"TRUNCATE TABLE \"MAKT\";",
"
CREATE TABLE \"MAKT\"(
\"MATNR\" VARCHAR(18),
\"SPRAS\" VARCHAR(2),
\"MAKTX\" VARCHAR(40));
"
)
}#Tip: ExistsTable(tableName) command allows to verify the existence of a table in a database.
Debugging #
Warning! Performance decrease! The performance decreases when bulk insert is disabled. Disable the bulk insert only when necessary, e.g., upon request of the support team.
By activating the checkbox Disable bulk operations, the default bulk insert is deactivated when writing to a database.
This option enables detailed error analysis, if certain data rows cannot be persisted on the database. Possible causes for the incorrect behavior could be incorrect values with regard to the stored data type.
Debugging needs to be deactivated again after the successful error analysis, otherwise the performance of the database write processes remains low.
Using Custom SQL
Note: Bulk operations are not supported when using Custom SQL statements (e.g., by Row Processing), which leads to performance decrease.
Tip: To increase performance when using Custom SQL statements, it is recommended to perform the custom processing in the Finalization step.
Transaction style #
Note: The available options for Transaction Style vary depending on the destination.
One Transaction
Preparation, Row Processing and Finalization are all performed in a single transaction.
Advantage: clean rollback of all changes.
Disadvantage: possibly extensive locking during the entire extraction period.
It is recommended to only use One Transaction in combination with DML commands, e.g., “truncate table” and “insert. Using DDL commands commits the active transaction, causing rollback issues for the steps after the DDL command. Example: If a table is created in the preparation step, the opened “OneTransaction” is committed and a rollback in the next steps is not performed correctly. For more information, see Snowflake Documentation: DDL Statements.
Three Transactions
Preparation, Row Processing and Finalization are each executed in a separate transaction.
Advantage: clean rollback of the individual sections, possibly shorter locking phases than with One Transaction (e.g. with DDL in Preparation, the entire DB is only locked during preparation and not for the entire extraction duration).
Disadvantage: No rollback of previous step possible (error in Row Processing only rolls back changes from Row Processing, but not Preparation).
RowProcessingOnly
Only Row Processing is executed in a transaction. Preparation and Finalization without an explicit transaction (implicit commits).
Advantage: DDL in ‘Preparation* and Finalization for DBMS that do not allow DDL in explicit transactions (e.g. AzureDWH)
Disadvantage: No rollback of Preparation/Finalization.
No Transaction
No explicit transactions.
Advantage: No transaction management required by DBMS (locking, DB transaction log, etc.). This means no locking and possible performance advantages.
Disadvantage: No rollback
Merging Database #
The following example depicts the update of the existing data records in a database by running an extraction to merge data. Merging in this case stands for changing a value of a field or inserting a new data row or updating an existing record.
Alternatively to merging, the data can be also updated by means of full load. The full load method is less efficient and performant.
Prerequisite for merging is a table with existing data, in which new data should be merged.
Ideally, the table with existing data is created in the initial load with the corresponding Preparation option and filled with data with the Row Processing option Insert.
Warning! Faulty merge
A primary key is a prerequisite for a merge command. If no primary key is set, the merge command runs into an error.
Create an appropriate primary key in the General Settings to execute the merge command.
Updated record in SAP #
A field value within an SAP table is updated. With a merge command the updated value is written to the destination database table.
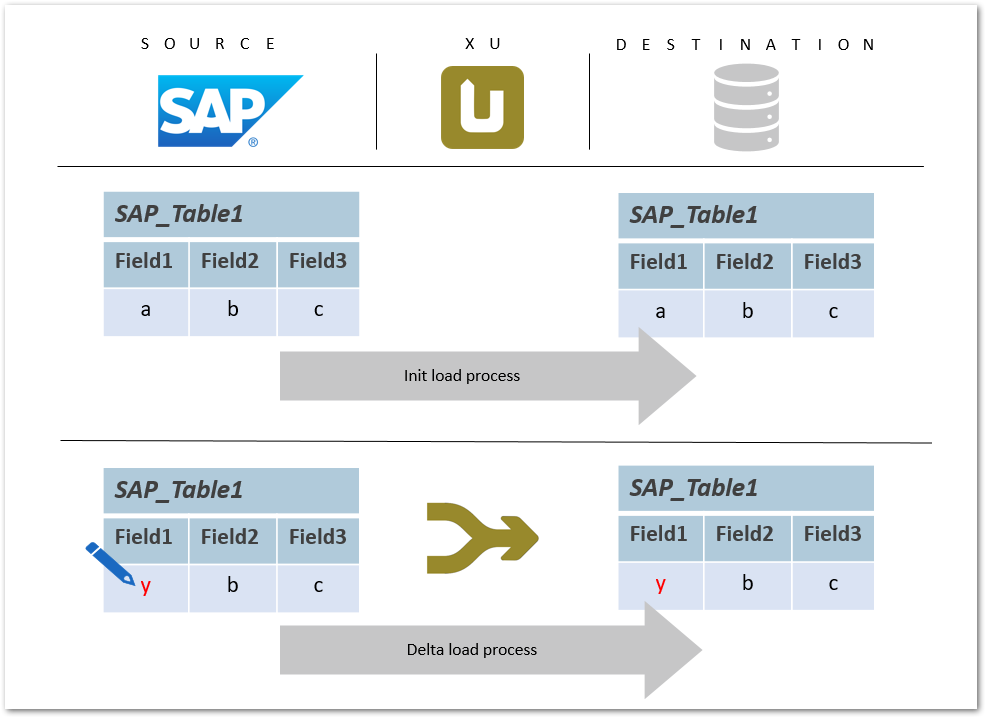
The merge command ensures delta processing: new records are inserted into the database and / or existing records are updated.
Merge command in Xtract Universal #
The merge process is performed using a staging table and takes place in three steps. In the first step, a temporary table is created in which the data is inserted in the second step. In the third step, the temporary table is merged with the target table and then the temporary table is deleted.
- In the main window of the Designer, select the respective extraction and click [Destination]. The window “Destination Settings” opens.
- Make sure to choose the correct destination: a database destination.
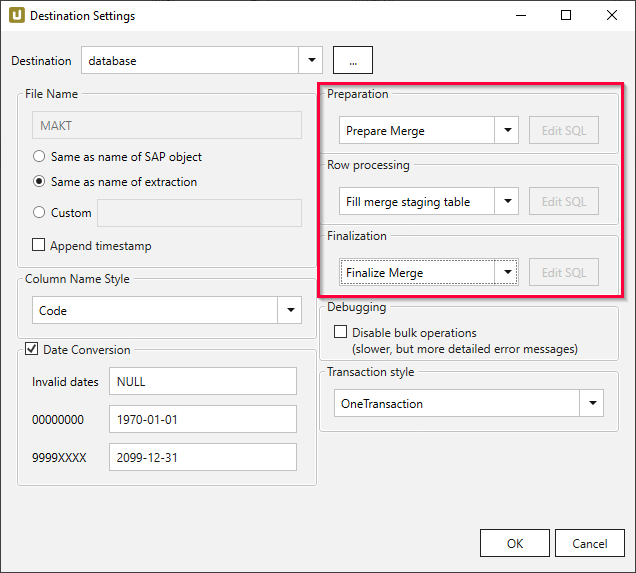
- Navigate to the right part of the “Destination Settings” window and apply the following settings:
- Preparation: Prepare Merge to create a temporary staging table
- Row Processing: Fill merge staging table to add data to the staging table
- Finalization: Finalize Merge to merge the staging table with the target table and then delete the staging table.
More information about the updated fields can be found in the SQL statement (Custom SQL only).
It is possible to edit the SQL statement if necessary, e.g., to exclude certain columns from the update.
Fields that do not appear in the SQL statement are not affected by changes.
Custom SQL #
Custom SQL Statement #
In the window Destination settings, you can use a custom SQL statement for the three different database process steps and / or to adapt the SQL statement to your requirements.
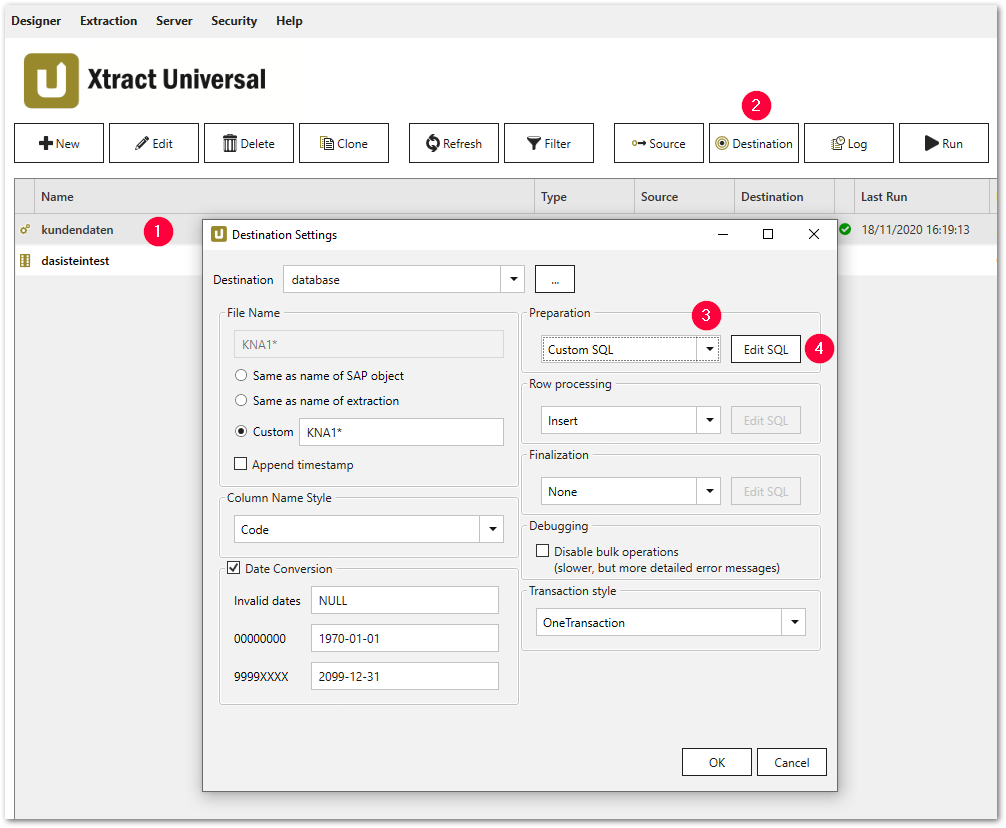
- Select a particular extraction (1).
- Click [Destination] (2), the window “Destination Settings” opens.
- Select the option Custom SQL from the drop-down list (3) in one of the following sections:
- Preparation
- Row Processing
- Finalization
- Click [Edit SQL] (4), the window “Edit SQL” opens.
Custom SQL Example #
In the following example, the table KNA1 is extended by a column with the current timestamp of type DATETIME.
The new column is filled dynamically using a .NET-based function.
Note: The data types that can be used in the SQL statement depend on the SQL Server database version.
- In the window “Destination Settings”, within the section Preparation, select Custom SQL and click [Edit SQL].
- In the drop-down menu, select the option Drop & Create and click [Generate Statement] (5).
- Add the following line in the generated statement:
[Extraction_Date] NATIONAL CHARACTER VARYING(23) - Confirm with [OK].
In the section Row Processing, the column values from SAP are processed in the previously created columns of the SQL target table. This SQL statement is therefore left on the standard Insert as an SQL statement. At this point, no data is written from the SAP source system, but NULL values are written to the newly created Extraction_Date column.
In the section section Finalization, the NULL values are filled with the following SQL statement of the current date of the extraction and written to the SQL target table by the T-SQL command UPDATE.
UPDATE [dbo].[KNA1]
SET [Extraction_Date] = '#{Extraction.Timestamp}#'
WHERE [Extraction_Date] IS NULL;
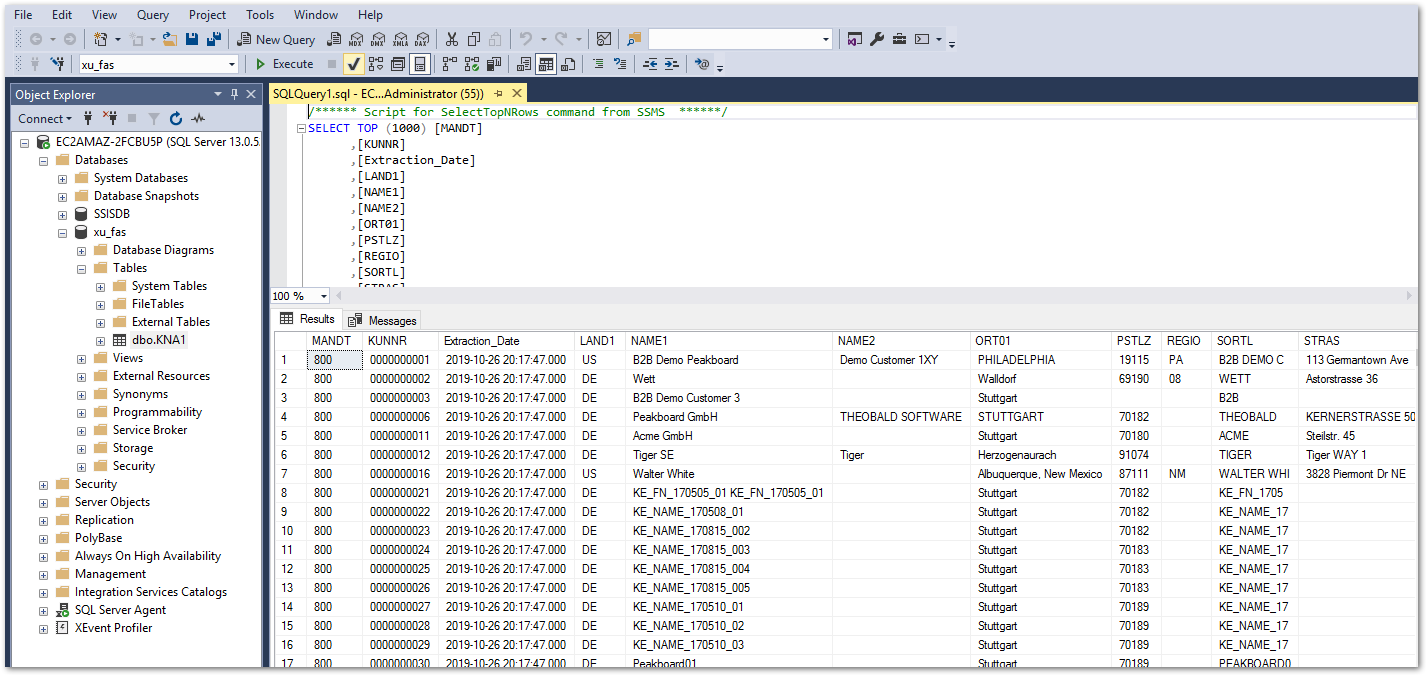
Checking the Result
Check the existence of the extended column Extraction_Date in the SQL Server View of table KNA1.
Creation of the SQL Table ExtractionStatistics #
The table “ExtractionStatistics” provides an overview and status of the executed Xtract Universal extractions.
To create the “ExtractionStatistics” table, create an SQL table according to the following example:
CREATE TABLE [dbo].[ExtractionStatistics](
[TableName] [nchar](50) NULL,
[RowsCount] [int] NULL,
[Timestamp] [nchar](50) NULL,
[RunState] [nchar](50) NULL
) ON [PRIMARY]
GO
The ExtractionStatistics table is filled in the Finalization DB process step, using the following SQL code:
INSERT INTO [ExtractionStatistics]
(
[TableName],
[RowsCount],
[Timestamp],
[RunState]
)
VALUES
(
'#{Extraction.TableName}#',
'#{Extraction.RowsCount}#',
'#{Extraction.Timestamp}#',
'#{Extraction.RunState}#'
);