Der folgende Abschnitt beschreibt die Extraktion von Daten nach Google Cloud Storage.
Google Cloud Platform (GCP) ist eine Sammlung von Cloud-Diensten bereitgestellt von Google. Google Cloud Platform ist verfügbar unter cloud.google.com. Google Cloud Storage ist einer der Google-Dienste zur Speicherung von Daten in der Google-Infrastruktur. Für mehr Informationen siehe Google Cloud Storage Dokumentation.
Voraussetzungen #
- Google account
- Google Cloud Platform (GCP) Abonnement (Demoversion wird angeboten)
- Projekt (“My First Project” ist vordefiniert)
- Google Cloud Storage (GCS) Bucket für Datenextraktionen
GCP-Konsole #
Die GCP-Konsole ermöglicht die Konfiguration aller Ressourcen und Dienste. Um zur Dashboard-Übersicht zu gelangen, navigieren Sie zur Google Cloud Storage Seite und klicken Sie auf [Console] oder [Go to console].
Um auf alle Einstellungen und Dienste zuzugreifen, verwenden Sie das Navigationsmenü auf der linken oberen Seite.
Verbindung #
Eine Destination hinzufügen #
- Navigieren Sie im Hauptfenster des Designers zu Server > Manage Destinations. Das Fenster “Manage Destination” wird geöffnet.
- Klicken Sie auf [Add], um eine neue Destination hinzufügen. Das Fenster “Destination Details” wird geöffnet.
- Geben Sie einen Namen für die Destination ein.
- Wählen Sie den Destinationstyp aus dem Dropdown-Menü aus.
Destination Details #
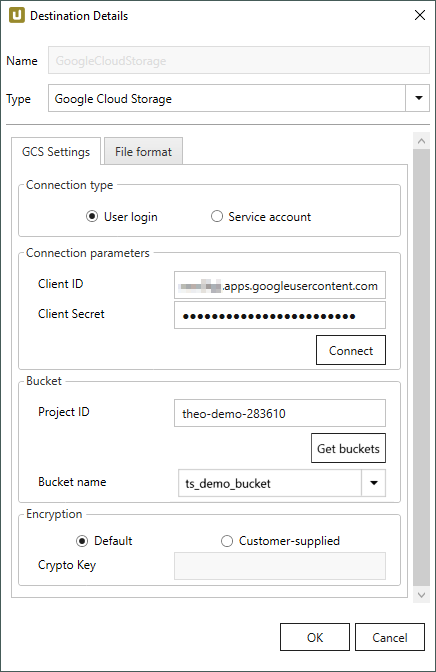
GCS Settings #
Connection Type
Es werden zwei Authentisierungsverfahren unterstützt:
- Wählen Sie User Login, um sich mit Ihrer OAuth Client ID einzuloggen, siehe Connection Parameters.
- Wählen Sie Service Account um sich mit einem Service-Account einzuloggen, siehe Service Acccount File Location.
Connection Parameters
Die folgenden Optionen sind nur verfügbar, wenn User Login als Authentifizierungsmethode ausgewählt ist.
Um das OAuth 2.0-Protokoll zur Authentifizierung zu aktivieren, konfigurieren Sie einen OAuth-Flow mit den erforderlichen Zugriffsberechtigungen auf Xtract Universal.
Für mehr Informationen siehe Knowledge Base Artikel: Setting Up OAuth 2.0 for the Google Cloud Storage Destination.
Client ID
Client ID erstellt im OAuth 2.0-Setup.
Client Secret
Client Secret erstellt im OAuth 2.0-Setup.
Connect
Verarbeitet den zuvor erstellten OAuth-Flow, um eine Verbindung mit dem Speicherkonto herzustellen.
Wählen Sie Ihr Google-Konto aus und gewähren Sie Xtract Universal Zugriff in allen erforderlichen Fenstern.
Hinweis: Wenn Sie die Anwendung nicht verifiziert haben, erscheint ein Fenster mit der Meldung: “This App isn’t verified” (Diese App ist nicht verifizert). Klicken Sie auf [Advanced] und [Go to Xtract Universal (unsafe)].
Nach einer erfolgreichen Verbindung erscheint die Meldung: “Authentication succeeded” (Authentifizierung erfolgreich) im Browser. In Xtract Universal wird die Meldung “Connection established” (Verbindung hergestellt” in einem separaten Fenster angezeigt.
Service Account File Location
Die folgenden Optionen sind nur verfügbar, wenn Service Account als Authentifizierungsmethode ausgewählt ist.
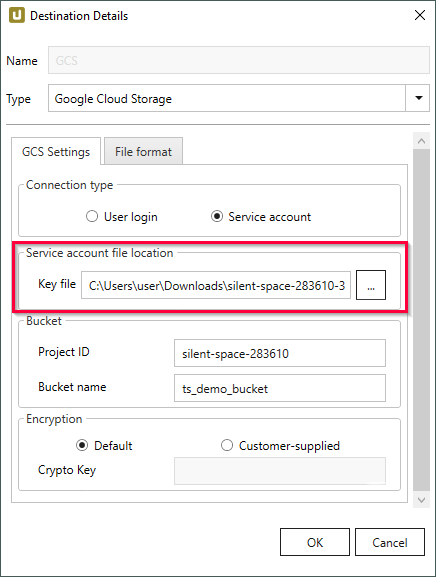
Key File
Das Service-Account wird über ein RSA Schlüsselpaar identifiziert.
Wenn Sie die Schlüssel erstellen, erhalten Sie eine Service-Accountdatei von Google, die Informationen über das Account enthält.
Geben Sie das Verzeichnis an, in dem die Service-Accountdatei abgelegt ist.
Stellen Sie sicher, dass der Xtract Universal Service Zugriff auf die Datei hat.
Bucket
Wenn Sie die OAuth 2.0 Authentifizierung verwenden, kann der Unterabschnitt “Bucket” erst nach einer erfolgreichen Verbindung zum Google-Cloud-Storage-Konto ausgefüllt werden.
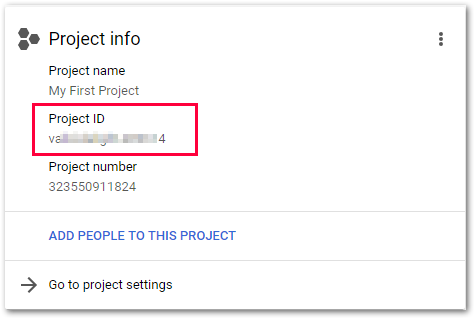
Project ID
Die Projekt-ID kann im GCP-Dashboard unter Project info nachgeschlagen werden.
Bucket name
Wenn Sie die OAuth 2.0 Authentifizierung verwenden, klicken Sie auf [Get buckets], um verfügbare Buckets anzeigen zu lassen.
Ein Bucket kann im Navigationsmenü unter Storage > Browser erstellt werden.
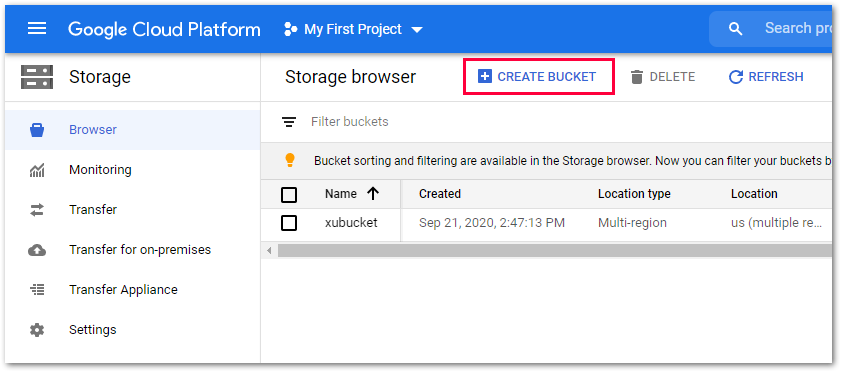
Sie können den Bucket-Namen (bucket name), den Standorttyp (location type) und die Storage-Klasse (storage class) oder die Zugriffskontrolle (access control) frei wählen.
Unter Advanced Settings (optional) können Sie die gewünschte Verschlüsselungsmethode auswählen, die auf den Bucket angewendet wird. Weitere Informationen zur Verschlüsselung finden Sie auf der offiziellen Google-Hilfeseite.
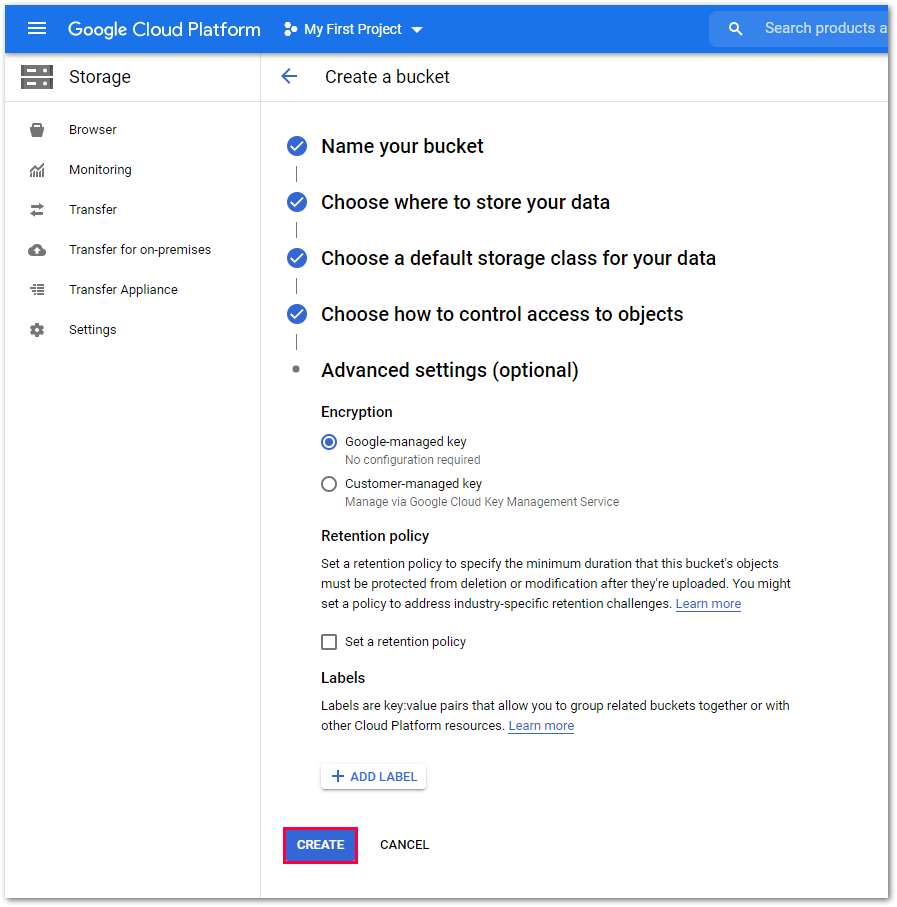
Encryption (Verschlüsselung)
Default
Wendet die in Ihrem GCS-Bucket angegebene Verschlüsselungsmethode an.
Google verschlüsselt standardmäßig alle Daten, die auf den Google-Servern gespeichert sind. Darüber hinaus können Sie den Google Cloud Key Management Service (KMS) nutzen, um Schlüssel zu erstellen und auf Ihre Buckets anzuwenden.
Der KMS kann im Navigationsmenü der GCP-Konsole aktiviert werden unter Security > Cryptographic Keys.
Customer-supplied
Wenn Sie die Option Customer-supplied ankreuzen, müssen Sie einen gültigen AES256-Kryptoschlüssel (256 Bit lang) angeben.
Der Kryptoschlüssel wird nicht innerhalb der GCP gespeichert und es erfordert daher zusätzlichen Aufbewahrungsaufwand, um Ihre Daten später entschlüsseln zu können.
Crypto field
Tragen Sie im Feld Crypto field den kryptografischen Schlüssel ein, wenn Sie “Customer Supplied” als Verschlüsselungsmethode gewählt haben.
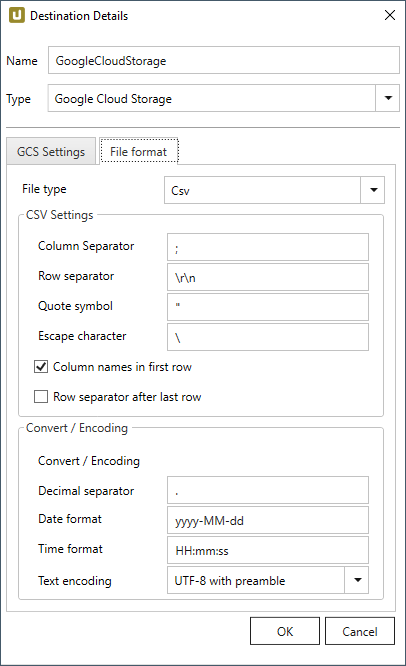
File Format #
Wählen Sie das gewünschte Dateiformat zwischen “CSV” ,”JSON” und “Parquet”.
CVS Settings
Die Einstellungen für den Dateityp CSV entsprechen den allgemeinen Flat File CSV Einstellungen.
Parquet Settings
Die folgenden Kompatibilitätsmodi sind verfügbar:
- Pure
- Spark
- BigQuery
Spark unterstützt nicht die im Pure-Mode verwendeten Datentypen, daher müssen andere Datentypen verwendet werden.
Sonderzeichen und Leerzeichen werden im Spark-Modus durch einen Unterstrich _ ersetzt.
| SAP | Pure / BigQuery | Spark |
|---|---|---|
| INT1 | UINT_8 | INT16 |
| TIMS | TIME_MILLIS | UTF8 |
Retry-Funktion #
Die Retry-Funktion ist eine eingebaute Funktion von der Google Cloud Storage Destination. Die Retry-Funktion ist automatisch aktiviert.
Die Retry-Funktion verhindert, dass Extraktionen fehlschlagen, wenn kurzzeitige Verbindungsunterbrechungen zu Google Cloud auftreten. Weitere allgemeine Informationen über Strategie der Wiederholversuche in einer Google Cloud Storage-Umgebung finden Sie in der offiziellen Google Cloud-Hilfe. Xtract Universal verfolgt eine exponentielle Strategie der Wiederholversuche. Dies bedeutet, dass 8 Verbindungsversuche gestartet werden in einem Zeitraum von 140 Sekunden. Sollte in dem Zeitraum von 140 Sekunden keine Verbindung zustande kommen, wird die Extraktion abgebrochen.
Einstellungen #
Destination Settings öffnen #
- Eine bestehende Extraktion anlegen oder auswählen, siehe Erste Schritte mit Xtract Universal.
- Klicken Sie auf [Destination]. Das Fenster “Destination Settings” wird geöffnet.
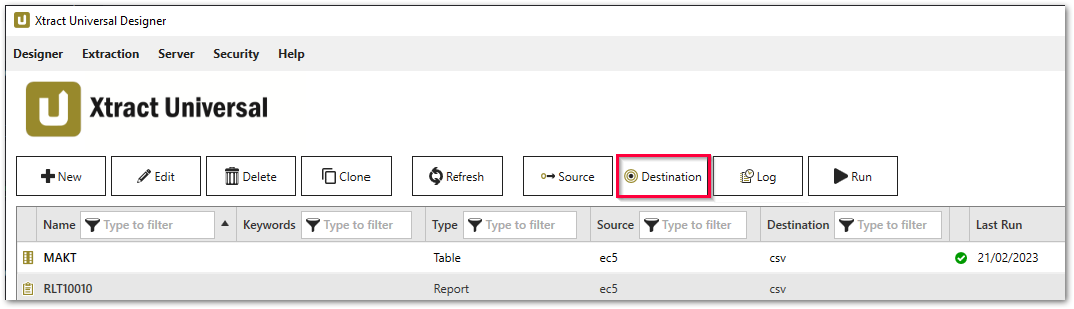
Die folgenden Einstellungen können für die Destination definiert werden.
Destination Settings - Destinationseinstellungen #
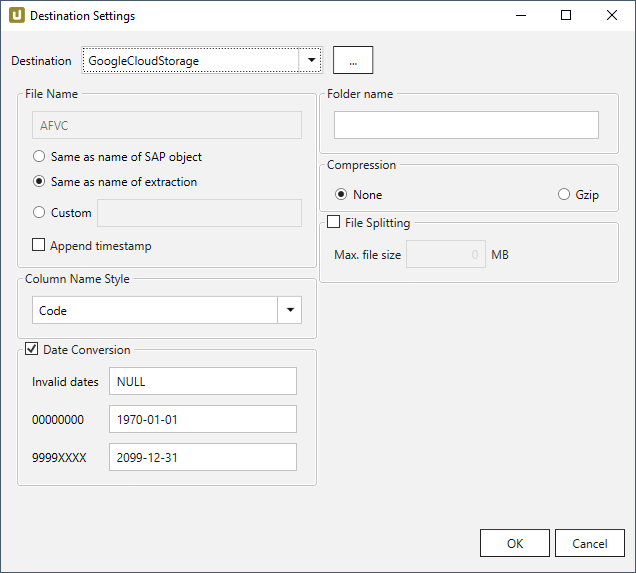
File Name #
File Name bestimmt den Namen der Zieltabelle. Sie haben die folgenden Optionen:
- Same as name of SAP object: Name des SAP-Objekts übernehmen
- Same as name of extraction: Name der Extraktion übernehmen
- Custom: Hier können Sie einen eigenen Namen definieren
- Append timestamp: fügt den Zeitstempel im UTC-Format (_YYYY_MM_DD_hh_mm_ss_fff) dem Dateinamen der Extraktion hinzu.
Hinweis: Wenn der Name eines Objekts nicht mit einem Buchstaben beginnt, wird ‘x’ als Präfix ergänzt, z.B. wird das Objekt _namespace_tabname.csv zu x_namespace_tabname.csv, wenn es auf die Destination hochgeladen wird.
Damit wird die Kompatibilität zu Azure Data Factory, Hadoop und Spark sichergestellt, die mit Buchstaben beginnende Objektnamen voraussetzen oder die nicht alphabetischen Zeichen besondere Bedeutungen zuweisen.
Skript-Ausdrücke als dynamische Dateinamen
Skript-Ausdrücke können für die Generierung eines dynamischen Dateinamens verwendet werden. Dadurch kann ein Name generiert werden, der sich aus den Eigenschaften einer Extraktion zusammensetzt, z.B. Extraktionsname, SAP-Quellobjekt. Unterstützt werden Skript-Ausdrücke, die auf .NET basieren, sowie folgende XU-spezifische Skript-Ausdrücke:
| Eingabe | Beschreibung |
|---|---|
#{Source.Name}# |
Name der SAP Quelle. |
#{Extraction.ExtractionName}# |
Name der Extraktion. Wenn die Extraktion Teil einer Extraktionsgruppe ist, geben Sie den Namen der Extraktionsgruppe vor dem Namen der Extraktion ein. Trennen Sie Gruppen mit ‘,’, z.B., Tables,KNA1, S4HANA,Tables,KNA1. |
#{Extraction.Type}# |
Extraktionstyp (Table, ODP, DeltaQ, etc.). |
#{Extraction.SapObjectName}# |
Name des SAP Objekts, von dem die Extraktion Daten extrahiert. |
#{Extraction.Timestamp}# |
Zeitstempel der Extraktion. |
#{Extraction.SapObjectName.TrimStart("/".ToCharArray())}# |
Entfernt einen führenden Schrägstrich, z.B. wird aus /BIO/TMATERIAL dann BIO/TMATERIAL, damit kein leeres Verzeichnis angelegt wird. |
#{Extraction.SapObjectName.Replace('/', '_')}# |
Entfernt alle Schrägstriche eines SAP Objekts, z.B. wird aus /BIO/TMATERIAL dann _BIO_TMATERIAL. Dadurch wird verhindert, dass die Schrägstriche innerhalb des Namens des SAP Objekts, nicht als Verzeichnistrenner interpretiert werden. |
#{Extraction.Context}# |
Nur für ODP Extraktionen: Kontext des ODP Objekts (SAPI, ABAP_CDS, etc.). |
#{Extraction.Fields["[NameSelectionFiels]"].Selections[0].Value}# |
Nur für ODP Extraktionen: Eingabewert einer definierten Selektion / eines Filter. |
#{Odp.UpdateMode}# |
Nur für ODP Extraktionen: Load-Verfahren (Delta, Full, Repeat) der Extraktion. |
#{TableExtraction.WhereClause}# |
Nur für Table Extraktionen: WHERE-Bedingung der Extraktion. |
Column Name Style #
Definiert den Spaltennamen. Folgende Optionen sind verfügbar:
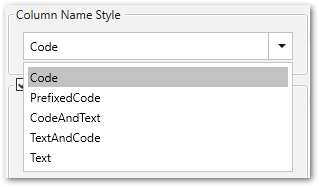
- Code: Der technische Spaltenname aus SAP wird als Spaltenname verwendet, z.B. MAKTX
- PrefixedCode: Der technische Name der Tabelle wird mit dem Tilde-Zeichen und dem entsprechenden Spaltennamen verbunden, z. B. MAKT~MAKTX.
- CodeAndText: Der technische Name und die Beschreibung der Spalte aus SAP mit einem Unterstrich verbunden werden als Spaltennamen verwendet, z.B. MAKTX_Material Description (Short Text).
- TextAndCode: Die Beschreibung und der technische Name der Spalte SAP mit einem Unterstrich verbunden werden als Spaltennamen verwendet, z.B. Material Description (Short Text)_MAKTX.
- Text: Die Beschreibung aus SAP wird als Spaltenname verwendet, z.B. Material Description (Short Text).
Date conversion #
Convert date strings
Konvertiert die Zeichenabfolge des SAP-Datums (YYYYMMDD, z.B. 19900101) zu einem formatierten Datum (YYYY-MM-DD, z.B. 1990-01-01). Im Datenziel hat das SAP-Datum keinen String-Datentyp sondern einen echten Datumstyp.
Convert invalid dates to
Falls ein SAP-Datum nicht in ein gültiges Datumsformat konvertiert werden kann, wird das ungültige Datum zu dem eingegebenen Wert konvertiert. NULL wird als Wert unterstützt.
Bei der Konvertierung eines ungültigen SAP-Datums werden zuerst die beiden Sonderfälle 00000000 und 9999XXXX überprüft.
Convert 00000000 to
Konvertiert das SAP-Datum 00000000 zu dem eingegebenen Wert.
Convert 9999XXXX to
Konvertiert das SAP-Datum 9999XXXX zu dem eingegebenen Wert.
Folder Name - Verzeichnisname #
Um Extraktionsdaten an einen Speicherort innerhalb eines bestimmten Ordners in einem Google Cloud Storage-Bucket zu schreiben, geben Sie einen Ordnernamen ohne Slashes ein.
Unterordner werden unterstützt und können mit der folgenden Syntax definiert werden:
[Verzeichnis]/[Unterverzeichnis_1]/[Unterverzeichnis_2]/…
Skript-Ausdrücke als dynamische Ordnerpfade
Skript-Ausdrücke können für die Generierung eines dynamischen Ordnerpfads verwendet werden. Dadurch kann ein Ordnerpfad generiert werden, der sich aus den Eigenschaften einer Extraktion zusammensetzt, z.B. Extraktionsname, SAP-Quellobjekt. Unterstützt werden Skript-Ausdrücke, die auf .NET basieren, sowie folgende XU-spezifische Skript-Ausdrücke:
| Eingabe | Beschreibung |
|---|---|
#{Source.Name}# |
Name der SAP Quelle. |
#{Extraction.ExtractionName}# |
Name der Extraktion. Wenn die Extraktion Teil einer Extraktionsgruppe ist, geben Sie den Namen der Extraktionsgruppe vor dem Namen der Extraktion ein. Trennen Sie Gruppen mit ‘,’, z.B., Tables,KNA1, S4HANA,Tables,KNA1. |
#{Extraction.Type}# |
Extraktionstyp (Table, ODP, DeltaQ, etc.). |
#{Extraction.SapObjectName}# |
Name des SAP Objekts, von dem die Extraktion Daten extrahiert. |
#{Extraction.Timestamp}# |
Zeitstempel der Extraktion. |
#{Extraction.SapObjectName.TrimStart("/".ToCharArray())}# |
Entfernt einen führenden Schrägstrich, z.B. wird aus /BIO/TMATERIAL dann BIO/TMATERIAL, damit kein leeres Verzeichnis angelegt wird. |
#{Extraction.SapObjectName.Replace('/', '_')}# |
Entfernt alle Schrägstriche eines SAP Objekts, z.B. wird aus /BIO/TMATERIAL dann _BIO_TMATERIAL. Dadurch wird verhindert, dass die Schrägstriche innerhalb des Namens des SAP Objekts, nicht als Verzeichnistrenner interpretiert werden. |
#{Extraction.Context}# |
Nur für ODP Extraktionen: Kontext des ODP Objekts (SAPI, ABAP_CDS, etc.). |
#{Extraction.Fields["[NameSelectionFields]"].Selections[0].Value}# |
Nur für ODP Extraktionen: Eingabewert einer definierten Selektion / eines Filter. |
#{Odp.UpdateMode}# |
Nur für ODP Extraktionen: Load-Verfahren (Delta, Full, Repeat) der Extraktion. |
#{TableExtraction.WhereClause}# |
Nur für Table Extraktionen: WHERE-Bedingung der Extraktion. |
#{Extraction.Fields["[0D_NW_CODE]"].Selections[0].Value}# |
Nur für BWCube Extraktionen (MDX Modus): Eingabewert einer definierten Selektion. |
#{Extraction.Fields["[0D_NW_CHANN]"].RangeSelections[0].LowerValue}# |
Nur für BWCube Extraktionen (MDX Modus): Niedriger Eingabewert eines definierten Selektionsbereichs. |
#{Extraction.Fields["[0D_NW_CHANN]"].RangeSelections[0].UpperValue}# |
Nur für BWCube Extraktionen (MDX Modus): Hoher Eingabewert eines definierten Selektionsbereichs. |
#{Extraction.Fields["0D_NW_CODE"].Selections[0].Value}# |
Nur für BWCube Extraktionen (BICS Modus): Eingabewert einer definierten Selektion. |
#{Extraction.Fields["0D_NW_CHANN"].RangeSelections[0].LowerValue}# |
Nur für BWCube Extraktionen (BICS Modus): Niedriger Eingabewert eines definierten Selektionsbereichs. |
#{Extraction.Fields["0D_NW_CHANN"].RangeSelections[0].UpperValue}# |
Nur für BWCube Extraktionen (BICS Modus): Hoher Eingabewert eines definierten Selektionsbereichs. |
Compression #
None
Die Daten werden unkomprimiert übertragen und als csv-Datei abgelegt.
gzip
Die Daten werden komprimiert übertragen und als gz-Datei abgelegt.
Hinweis: Diese Option ist nur für das csv-Dateiformat verfügbar, siehe Verbindung: File Format.
File Splitting #
File Splitting
Schreibt die Extraktionsdaten einer einzelnen Extraktion in mehrere Dateien im die Cloud. Dabei wird an jeden Dateinamen _part[nnn] angehägt.
Max. file size
Geben Sie die Maximalgröße der Dateien ein, die hochgeladen werden sollen.
Note: Die Option Max. file size wird nicht von gzip-Dateien unterstützt. Die Größe von durch gzip-Verfahren komprimierten Dateien kann nicht im Voraus bestimmt werden.