Der folgende Abschnitt behandelt das Laden der SAP-Extraktionsdaten in eine Snowflake-Umgebung.
Voraussetzungen #
Die Anbindung an die Snowflake Zielumgebung erfolgt über den ODBC-Treiber für Windows 64-Bit Architekturen.
Es sind keine zusätzlichen Installationen für die Nutzung der Snowflake Destination erforderlich.
- Installieren Sie den SnowflakeDSIIDriver.
- Konfigurieren Sie die folgenden Umgebungsvariablen, um sich mit einem Proxy-Server zu verbinden:
http_proxy,https_proxy,no_proxy.
Für mehr Informationen, siehe Snowflake: ODBC Configuration and Connection Parameters. - Der ODBC Port (443) für HTTPS muss freigegeben sein und ausgehenden Traffic vom Netzwerk zu Snowflake erlauben.
- Das Snowflake-Konto, mit dem Daten auf Snowflake hochgeladen werden, braucht entsprechende Zugriffsberechtigungen, siehe Snowflake Documentation: Übersicht zur Zugriffssteuerung - Rollen.
Die folgenden Berechtigungen sind Voraussetzung:
- PUT-Befehl
- COPY-Befehl
- TABLE
Verbindung #
Eine Destination hinzufügen #
- Navigieren Sie im Hauptfenster des Designers zu Server > Manage Destinations. Das Fenster “Manage Destination” wird geöffnet.
- Klicken Sie auf [Add], um eine neue Destination hinzufügen. Das Fenster “Destination Details” wird geöffnet.
- Geben Sie einen Namen für die Destination ein.
- Wählen Sie den Destinationstyp aus dem Dropdown-Menü aus.
Destination Details #
General
Connection
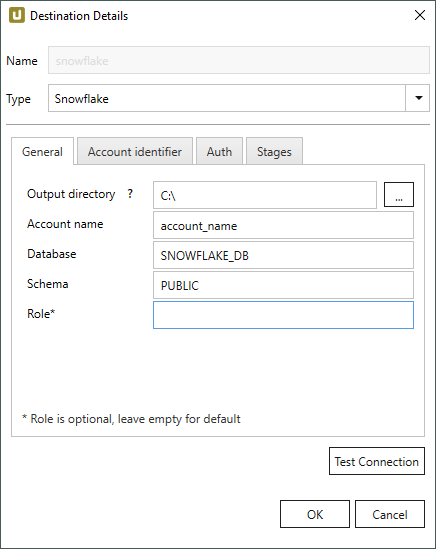
Output directory
Geben Sie ein lokalen Verzeichnis an, in das die extrahierten Daten als csv-Datei abgelegt werden.
Prozess während der Extraktion:
- Im lokalen Verzeichnis wird eine csv-Datei erstellt.
- Wenn die Datei eine bestimmte Größe erreicht hat, wird sie gezippt (gzip), siehe File Splitting.
- Die gezippte Datei wird via PUT-Befehl in den Snowflake Staging-Bereich hochgeladen.
- Die Daten per COPY-Befehl in die entsprechende Snowflake-Tabelle kopiert.
Dieser Prozess (gzip + PUT command) wiederholt sich solange, bis die Extraktion abgeschlossen ist.
Das lokale Verzeichnis und der Staging-Bereich werden im Verlauf der Extraktion geleert, d.h., die erzeugten csv-Dateien werden wieder gelöscht.
Account Name
Geben Sie den Kontonamen ein.
Der Kontoname kann aus der Verbindungs-URL abgeleitet werden.
URL für Kontonamen innerhalb einer Organisation: https://[organization]-[account_name].snowflakecomputing.com/console#/
URL für Konto-Locator in einer Region (veraltet): https://[account_name].[region].[cloud].snowflakecomputing.com/console#/
Database
Geben Sie den Namen der Datenbank ein.
Schema
Geben Sie das Schema der Datenbank ein.
Role
Geben Sie eine Benutzerrolle ein.
Wenn keine Benutzerrolle angegeben ist, wird die Standard-Benutzerrolle für die Verbindung zu Snowflake verwendet.
Acount Identifier
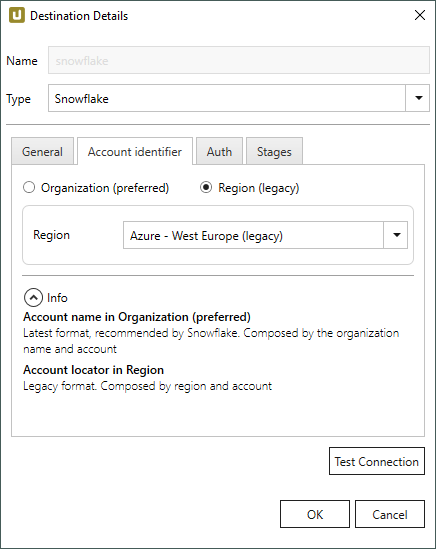
Organization (preferred)
Geben Sie den Namen der Organisation an.
Die Identifizierung über den Kontonamen in einer Organisation ist die von Snowflake bevorzugte Authentifizierungsmethode, siehe Snowflake Dokumentation: Kontoname in Ihrer Organisation
Region (legacy)
Wählen Sie die Region der Snowflake-Umgebung aus.
In diesem Beispiel ist die Region AWS - EU (Frankfurt) ausgewählt. Die gewählte Region muss den Angaben im zugewiesen Account entsprechen.
Hinweis: Regionen mit dem Suffix (legacy) sind veraltet. Die Cloud Region ID dieser Regionen wurde von Snowflake umbenannt.
Wählen Sie die (legacy)-Option, wenn Sie sich über einen Link mit einer alten Cloud Region ID mit Snowflake verbinden.
Für mehr Informationen zu den aktuellen Cloud Region IDs, siehe Snowflake Dokumentation: Supported Cloud Regions.
Authentication
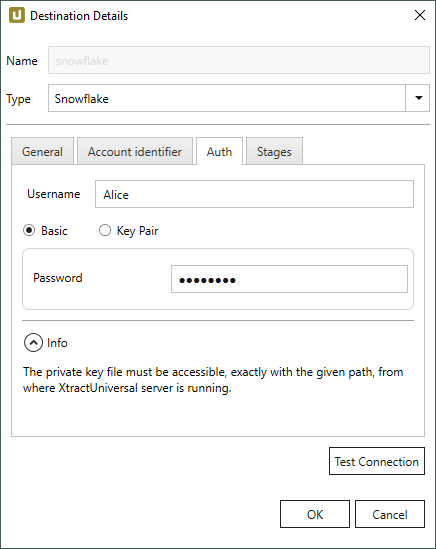
Username
Geben Sie den Namen des Benutzers ein.
Basic
Wenn diese Option aktiv ist, wird Basic Authentication für die Authentifizierung verwendet.
Geben Sie das Passwort des Benutzers im Feld Password ein.
Key Pair
Wenn diese Option aktiv ist, werden Schlüsselpaare für die Authentifizierung verwendet, siehe Snowflake Dokumentation: Schlüsselpaar-Authentifizierung und Schlüsselpaar-Rotation.
Im Feld Private Key Path wählen Sie den Pfad aus, in dem Ihr privater Schlüssel abgelegt ist. Verschlüsselte und unverschüsselte Schlüssel werden unterstützt. Wenn Sie verschlüsselte Schlüssel verwenden, geben Sie das Passwort zum entschlüsseln im Feld Key password an.
Stages
Klicken Sie auf [Test Connection], um alle verfügbaren Stages und Data Warehouses von Snowflake abzurufen.
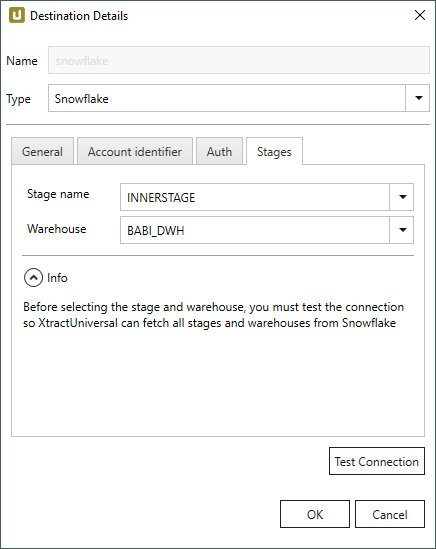
Stage name
Wählen Sie eine Stage aus.
Beachten Sie, dass nur “Internal” Stages unterstützt werden.
Warehouse
Wählen Sie ein Snowflake Data Warehouse aus.
Einstellungen #
Destination Settings öffnen #
- Eine bestehende Extraktion anlegen oder auswählen, siehe Erste Schritte mit Xtract Universal.
- Klicken Sie auf [Destination]. Das Fenster “Destination Settings” wird geöffnet.
Die folgenden Einstellungen können für die Destination definiert werden.
Destination Settings - Destinationseinstellungen #
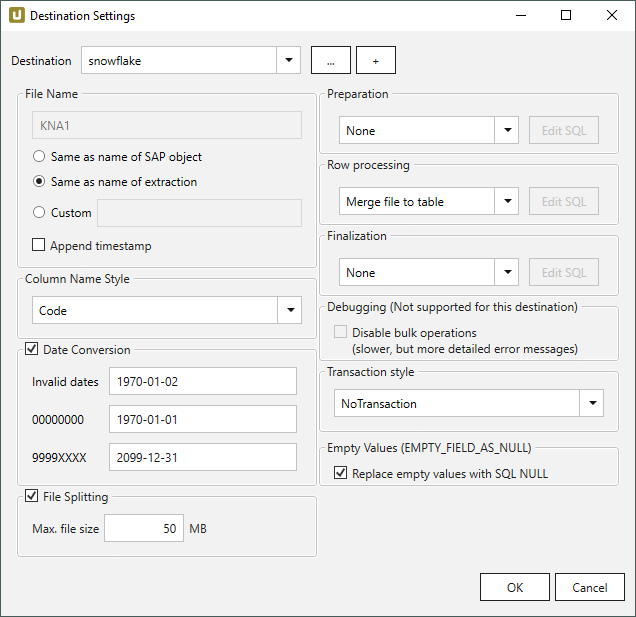
File Name #
File Name bestimmt den Namen der Zieltabelle. Sie haben die folgenden Optionen:
- Same as name of SAP object: Name des SAP-Objekts übernehmen
- Same as name of extraction: Name der Extraktion übernehmen
- Custom: Hier können Sie einen eigenen Namen definieren
- Append timestamp: fügt den Zeitstempel im UTC-Format (_YYYY_MM_DD_hh_mm_ss_fff) dem Dateinamen der Extraktion hinzu.
Skript-Ausdrücke als dynamische Dateinamen
Skript-Ausdrücke können für die Generierung eines dynamischen Dateinamens verwendet werden. Dadurch kann ein Name generiert werden, der sich aus den Eigenschaften einer Extraktion zusammensetzt, z.B. Extraktionsname, SAP-Quellobjekt. Unterstützt werden Skript-Ausdrücke, die auf .NET basieren, sowie folgende XU-spezifische Skript-Ausdrücke:
| Eingabe | Beschreibung |
|---|---|
#{Source.Name}# |
Name der SAP Quelle. |
#{Extraction.ExtractionName}# |
Name der Extraktion. Wenn die Extraktion Teil einer Extraktionsgruppe ist, geben Sie den Namen der Extraktionsgruppe vor dem Namen der Extraktion ein. Trennen Sie Gruppen mit ‘,’, z.B., Tables,KNA1, S4HANA,Tables,KNA1. |
#{Extraction.Type}# |
Extraktionstyp (Table, ODP, DeltaQ, etc.). |
#{Extraction.SapObjectName}# |
Name des SAP Objekts, von dem die Extraktion Daten extrahiert. |
#{Extraction.Timestamp}# |
Zeitstempel der Extraktion. |
#{Extraction.SapObjectName.TrimStart("/".ToCharArray())}# |
Entfernt einen führenden Schrägstrich, z.B. wird aus /BIO/TMATERIAL dann BIO/TMATERIAL, damit kein leeres Verzeichnis angelegt wird. |
#{Extraction.SapObjectName.Replace('/', '_')}# |
Entfernt alle Schrägstriche eines SAP Objekts, z.B. wird aus /BIO/TMATERIAL dann _BIO_TMATERIAL. Dadurch wird verhindert, dass die Schrägstriche innerhalb des Namens des SAP Objekts, nicht als Verzeichnistrenner interpretiert werden. |
#{Extraction.Context}# |
Nur für ODP Extraktionen: Kontext des ODP Objekts (SAPI, ABAP_CDS, etc.). |
#{Extraction.Fields["[NameSelectionFiels]"].Selections[0].Value}# |
Nur für ODP Extraktionen: Eingabewert einer definierten Selektion / eines Filter. |
#{Odp.UpdateMode}# |
Nur für ODP Extraktionen: Load-Verfahren (Delta, Full, Repeat) der Extraktion. |
#{TableExtraction.WhereClause}# |
Nur für Table Extraktionen: WHERE-Bedingung der Extraktion. |
Column Name Style #
Definiert den Spaltennamen. Folgende Optionen sind verfügbar:
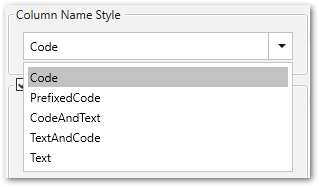
- Code: Der technische Spaltenname aus SAP wird als Spaltenname verwendet, z.B. MAKTX
- PrefixedCode: Der technische Name der Tabelle wird mit dem Tilde-Zeichen und dem entsprechenden Spaltennamen verbunden, z. B. MAKT~MAKTX.
- CodeAndText: Der technische Name und die Beschreibung der Spalte aus SAP mit einem Unterstrich verbunden werden als Spaltennamen verwendet, z.B. MAKTX_Material Description (Short Text).
- TextAndCode: Die Beschreibung und der technische Name der Spalte SAP mit einem Unterstrich verbunden werden als Spaltennamen verwendet, z.B. Material Description (Short Text)_MAKTX.
- Text: Die Beschreibung aus SAP wird als Spaltenname verwendet, z.B. Material Description (Short Text).
Date conversion #
Convert date strings
Konvertiert die Zeichenabfolge des SAP-Datums (YYYYMMDD, z.B. 19900101) zu einem formatierten Datum (YYYY-MM-DD, z.B. 1990-01-01). Im Datenziel hat das SAP-Datum keinen String-Datentyp sondern einen echten Datumstyp.
Convert invalid dates to
Falls ein SAP-Datum nicht in ein gültiges Datumsformat konvertiert werden kann, wird das ungültige Datum zu dem eingegebenen Wert konvertiert. NULL wird als Wert unterstützt.
Bei der Konvertierung eines ungültigen SAP-Datums werden zuerst die beiden Sonderfälle 00000000 und 9999XXXX überprüft.
Convert 00000000 to
Konvertiert das SAP-Datum 00000000 zu dem eingegebenen Wert.
Convert 9999XXXX to
Konvertiert das SAP-Datum 9999XXXX zu dem eingegebenen Wert.
File Splitting #
File Splitting
Schreibt die Extraktionsdaten einer einzelnen Extraktion in mehrere Dateien im die Cloud. Dabei wird an jeden Dateinamen _part[nnn] angehägt.
Max. file size
Geben Sie die Maximalgröße der Dateien ein, die hochgeladen werden sollen.
Note: Die Option Max. file size wird nicht von gzip-Dateien unterstützt. Die Größe von durch gzip-Verfahren komprimierten Dateien kann nicht im Voraus bestimmt werden.
Preparation - SQL Anweisungen #
Aktion auf der Zieldatenbank, bevor die Daten in die Zieltabelle eingefügt werden.
- Drop & Create: Tabelle entfernen falls vorhanden und neu anlegen (Default).
- Truncate Or Create: Tabelle entleeren falls vorhanden, sonst anlegen.
- Truncate: Tabelle entleeren falls vorhanden.
- Create If Not Exists: Tabelle anlegen falls nicht vorhanden.
- None: keine Aktion
- Custom SQL: Hier können Sie eigenes Skript definieren. Siehe den unteren Abschnitt Custom SQL.
Wollen Sie im ersten Schritt nur die Tabelle anlegen und keine Daten einfügen, dann haben Sie zwei Möglichkeiten:
- Sie kopieren das SQL-Statement und führen es direkt auf der Zieldaten-Datenbank aus.
- Sie wählen die Option None für Row Processing und führen die Extraktion aus.
Nachdem die Tabelle angelegt ist, bleibt es Ihnen überlassen, die Tabellendefinition zu ändern, indem Sie bspw. entsprechende Schlüsselfelder und Indizes bzw. zusätzliche Felder anlegen.
Row Processing - SQL Anweisungen #
Definiert, wie die Daten in die Zieltabelle eingefügt werden.
- None: keine Aktion.
- Copy file to table: Datensätze einfügen (Default).
- Merge File to table: Datensätze in die Staging-Tabelle einfügen.
- Custom SQL: Hier können Sie eigenes Skript definieren. Siehe den unteren Abschnitt Custom SQL.
Finalization - SQL Anweisungen #
Aktion auf der Zieldatenbank, nachdem die Daten in die Zieltabelle erfolgreich eingefügt werden.
- None: keine Aktion (Default).
- Custom SQL: Hier können Sie eigenes Skript definieren. Siehe den unteren Abschnitt Custom SQL.
Über Merging
Die Zusammenführung gewährleistet eine Deltaverarbeitung: neue Datensätze werden in die Datenbank eingefügt und/oder bestehende Datensätze werden aktualisiert. Mehr Details im Abschnitt Daten zusammenführen (mergen).
Custom SQL #
Die Option Custom SQL ermöglicht die Erstellung benutzerdefinierter SQL-Anweisungen. Vorhandene SQL-Befehle können als Vorlagen verwendet werden:
- Wählen Sie im Unterabschnitt z.B. Preparation die Option Custom SQL (1) aus der Dropdown-Liste.
- Klicken Sie auf [Edit SQL]. das Fenster “Edit SQL” wird geöffnet.
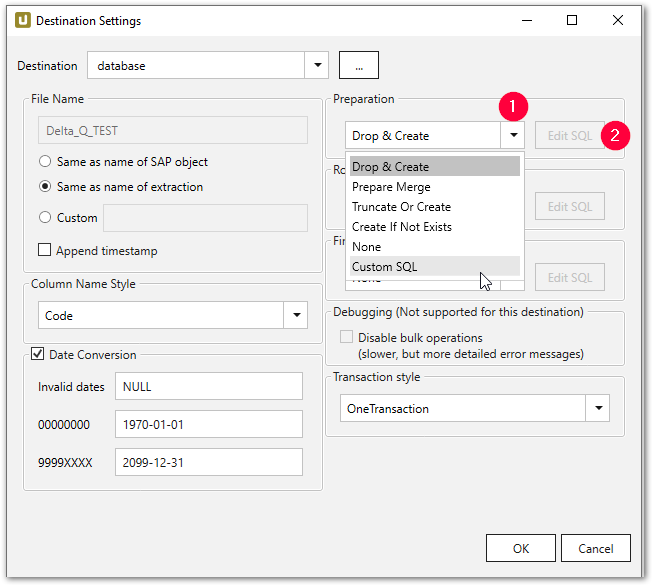
- Navigieren Sie zum Dropdown-Menü und wählen Sie einen vorhandenen Befehl (3).
- Klicken Sie auf [Generate Statement]. Eine neue Anweisung wird generiert.
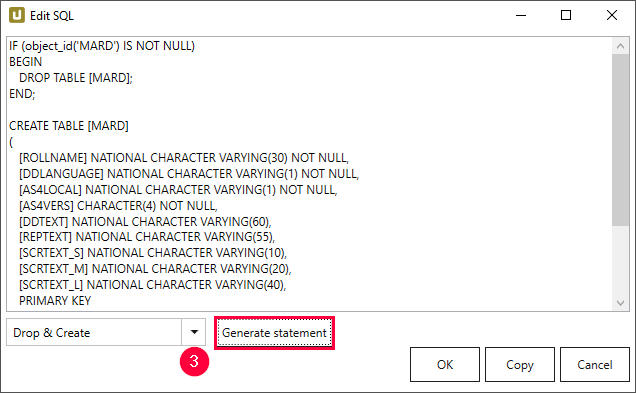
- Klicken Sie auf [Copy] um die Anweisung in den Zwischenspeicher zu kopieren.
- Klicken Sie zur Bestätigung auf [OK].
Vorlagen
Sie können eigene SQL-Ausdrücke schreiben und haben damit die Möglichkeit, das Laden der Daten an Ihre Bedürfnisse anzupassen.
Darüber hinaus können Sie z.B. auch auf der Datenbank bestehende “Stored Procedures” ausführen.
Dafür können Sie die vordefinierten SQL-Vorlagen der folgenden Phasen verwenden:
- Preparation (z.B. Drop & Create oder Create if Not Exists)
- Row Processing (z.B. Merge) und
- Finalization
Hinweis: Für nähere Informationen zu benutzerdefinierten SQL-Anweisungen, siehe Custom SQL.
Transaction style #
Hinweis: Je nach Destination variieren die verfügbaren Optionen für Transaction Style.
One Transaction
Preparation, Row Processing und Finalization werden in einer einer einzigen Transaktion ausgeführt.
Vorteil: sauberer Rollback aller Änderungen.
Nachteil: ggf. umfangreiches Locking während der gesamten Extraktionsdauer.
Es ist empfohlen, One Transaction nur in Kombination mit DML-Befehlen zu verwenden, z. B. „truncate table“ und „insert“.
Durch die Verwendung von DDL-Befehlen wird die aktive Transaktion festgeschrieben, was zu Rollback-Problemen für die Schritte nach dem DDL-Befehl führt.
Beispiel: Wenn im Vorbereitungsschritt eine Tabelle erstellt wird, wird die geöffnete „OneTransaction“ festgeschrieben und ein Rollback in den nächsten Schritten wird nicht korrekt durchgeführt.
Weitere Informationen finden Sie unter Snowflake Documentation: DDL Statements.
Three Transactions
Prepare, Row Processing und Finalization werden jeweils in einer eigenen Transaktion ausgeführt.
Vorteil: sauberer Rollback der einzelnen Abschnitte, evtl. kürzere Locking-Phasen als bei One Transaction (z. B. bei DDL in Preparation wird die gesamte DB nur bei Preparation gelockt und nicht für die gesamte Extraktionsdauer)
Nachteil: Kein Rollback von vorangegangen Schritt möglich (Fehler im Row Processing rollt nur Änderungen aus Row Processing zurück, nicht aus Preparation).
RowProcessingOnly
Nur Row Processing wird in einer Transaktion ausgeführt. Preparation und Finalization ohne explizite Transaktion (implizite commits).
Vorteil: DDL in Perparation und Finalization bei DBMS, die kein DDL in expliziten Transaktionen zulassen (z. B. AzureDWH).
Nachteil: Kein Rollback von Preparation/Finalization.
No Transaction
Keine expliziten Transaktionen.
Vorteil: Keine Transaktionsverwaltung durch DBMS benötigt (Locking, DB-Transaktionslog, etc.). Dadurch kein Locking und evtl. Performanzvorteile.
Nachteil: Kein Rollback.
Empty Values #
Warnung! NULL result in a non-nullable column. Standardmäßig werden leere Strings in Snowflake zu Null-Werten konvertiert. Um die Konvertierung nicht durchzuführen, deaktivieren Sie Replace empty values with SQL NULL.
Replace empty values with SQL NULL
Diese Option kontrolliert den Snowflake Parameter EMPTY_FIELD_AS_NULL.
Wenn Replace empty values with SQL NULL aktiv ist, werden leere Strings beim Upload nach Snowflake zu NULL-Werten konvertiert.
Daten Mergen #
Das folgende Beispiel zeigt die Aktualisierung der vorhandenen Datensätze in einer Datenbank durch Ausführen einer Extraktion. Dabei geht es um Zusammenzuführen (Merge) der Daten, d.h. z.B. den Wert eines Feldes zu ändern oder eine neue Datenzeile einzufügen oder eine vorhandene zu aktualisieren.
Alternativ zum Zusammenführen (Merge) können die Datensätze durch einen “Full Load” aktualisiert werden. Das Full-Load-Verfahren ist weniger effizient und performant.
Voraussetzung für das Zusammenführen (Merge) ist eine Tabelle mit vorhandenen Daten, in welche neue Daten zusammengeführt werden sollen.
Im Idealfall wird die Tabelle mit den vorhandenen Daten im initialen Lauf erstellt und mit der Option Merge file to table in Row Processing befüllt.
Warnung! Fehlerhaftes Zusammenführen
Ein Primärschlüssel ist eine Voraussetzung für einen Merge-Befehl. Wenn kein Primärschlüssel gesetzt ist, läuft der Zusammenführungsbefehl in einen Fehler.
Erstellen Sie einen entsprechenden Primärschlüssel in General Settings, um den Merge-Befehl ausführen zu können.
Aktualisierter Datensatz in SAP #
Ein Feldwert innerhalb einer SAP-Tabelle wird aktualisiert. Mit einem Merge-Befehl wird der aktualisierte Wert in die Zieldatenbanktabelle geschrieben.
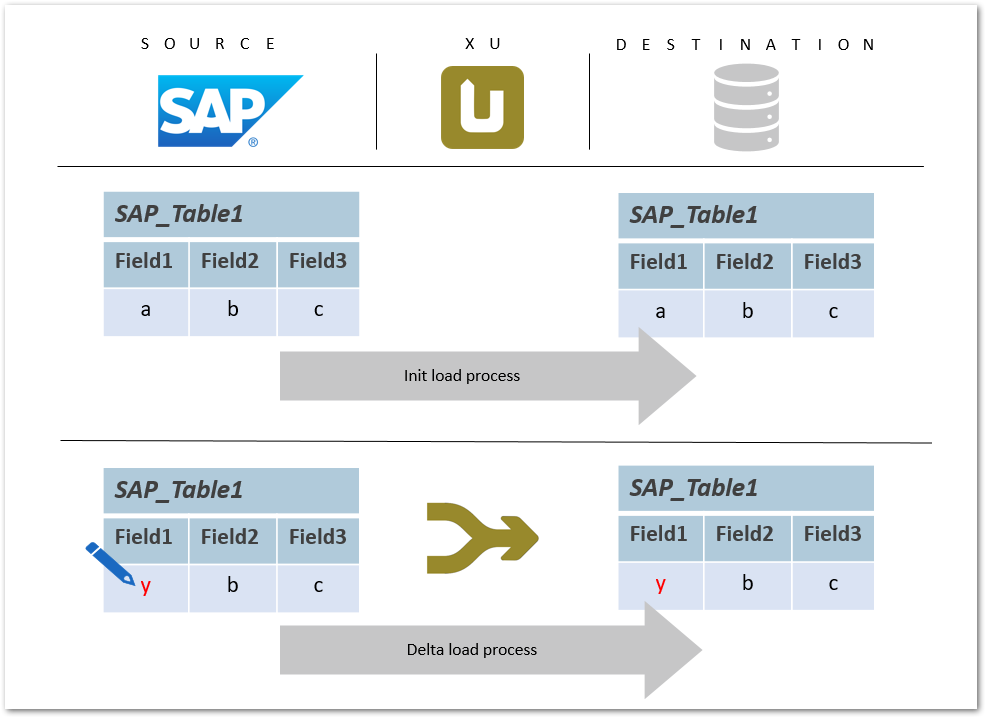
Der Merge-Befehl gewährleistet eine Deltaverarbeitung: neue Datensätze werden in die Datenbank eingefügt und/oder bestehende Datensätze aktualisiert.
Merge-Befehl in Xtract Universal #
Der Merge-Prozess wird mit Hilfe einer Staging-Tabelle durchgeführt und erfolgt in drei Schritten. Im ersten Schritt wird eine temporäre Tabelle angelegt, in die die Daten im zweiten Schritt eingefügt werden. Im dritten Schritt wird die temporäre Tabelle mit der Zieltabelle zusammengeführt und anschließend wird die temporäre Tabelle gelöscht.
- Wählen Sie im Hauptfenster des Designers die entsprechende Extraktion aus und klicken Sie auf [Destination]. Das Fenster “Destination Settings” wird geöffnet.
- Stellen Sie sicher, dass Sie die passende Destination wählen: eine Datenbankdestination.
- Navigieren Sie zum rechten Teil des Fensters “Destination Settings” und wenden Sie die folgenden Einstellungen an:
- Preparation: None
- Row Processing: Merge file to table, um die Staging-Tabelle mit Dateien zu befüllen.
- Finalization: None
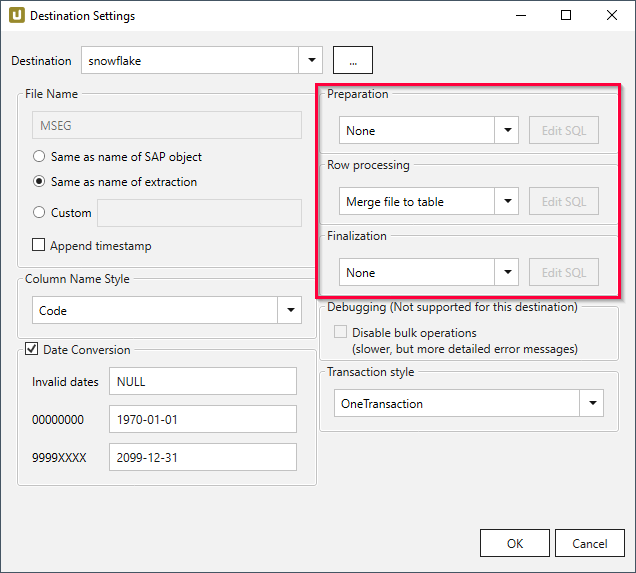
Weitere Informationen über die aktualisierten Felder finden Sie in der SQL-Anweisung (nur Custom SQL).
Es ist möglich, die SQL-Anweisung bei Bedarf zu bearbeiten, z.B. bestimmte Spalten von der Aktualisierung auszuschließen.
Felder, die nicht in der SQL-Anweisung erscheinen, sind von den Änderungen nicht betroffen.
Custom SQL #
Custom SQL Statement - Benutzerdefinierte SQL-Anweisung #
Im Fenster Destination settings können Sie eine benutzerdefinierte SQL-Anweisung für die drei verschiedenen Datenbank-Prozessschritte verwenden und / oder die SQL-Anweisung an Ihre Anforderungen anpassen.
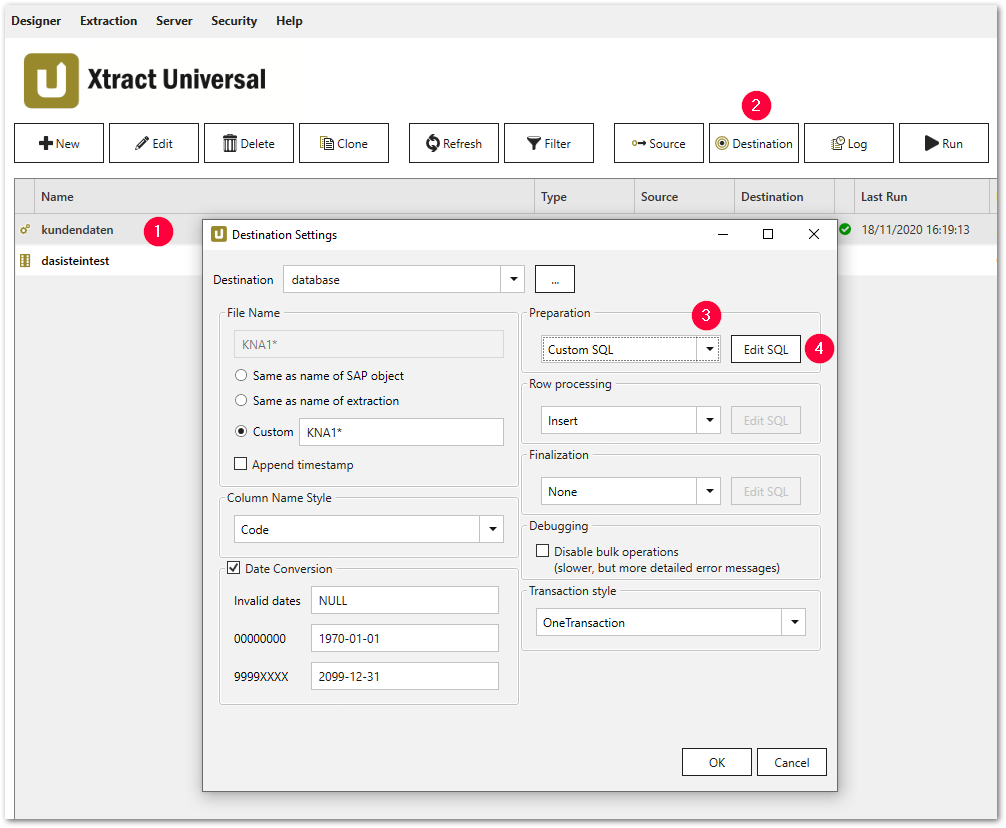
- Wählen Sie eine bestimmte Extraktion (1).
- Klicken Sie auf [Destination] (2), das Fenster “Destination Settings” wird geöffnet.
- Wählen Sie die Option Custom SQL aus der Dropdown-Liste (3) in einem der folgenden Abschnitte:
- Preparation
- Row Processing
- Finalization
- Klicken Sie auf [Edit SQL] (4). Das Fenster “Edit SQL” öffnet sich.
Custom SQL Beispiel #
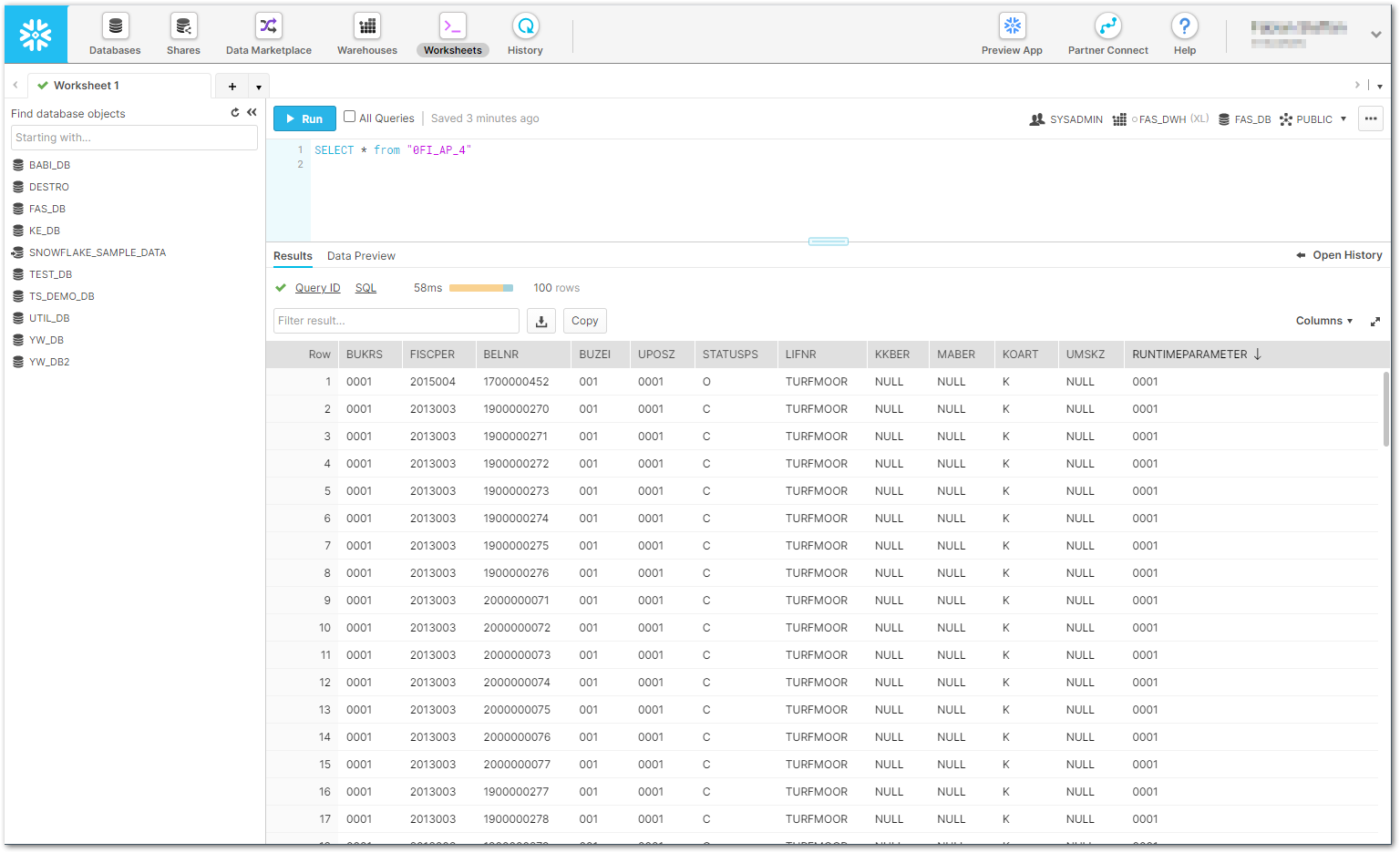
Im folgenden Beispiel wird die DataSource 0FI_AP_4 um eine Spalte mit dem benutzerdefinierten Laufzeitparameter RUNTIMEPARAMETER erweitert.
Das Füllen der neuen Spalte wird im Abschnitt Finalisierung der Destinationseinstellungen dynamisch implementiert.
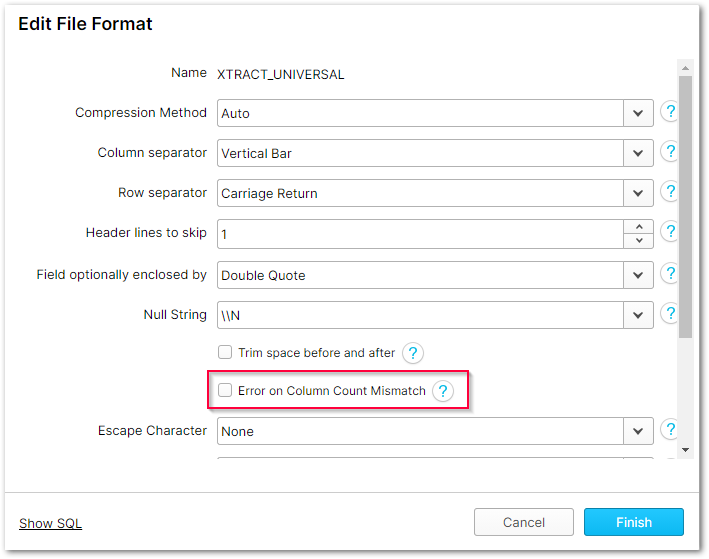
- Deselektieren Sie die Option Error on Column Count Mismatch im XTRACT_UNIVERSAL File Format.
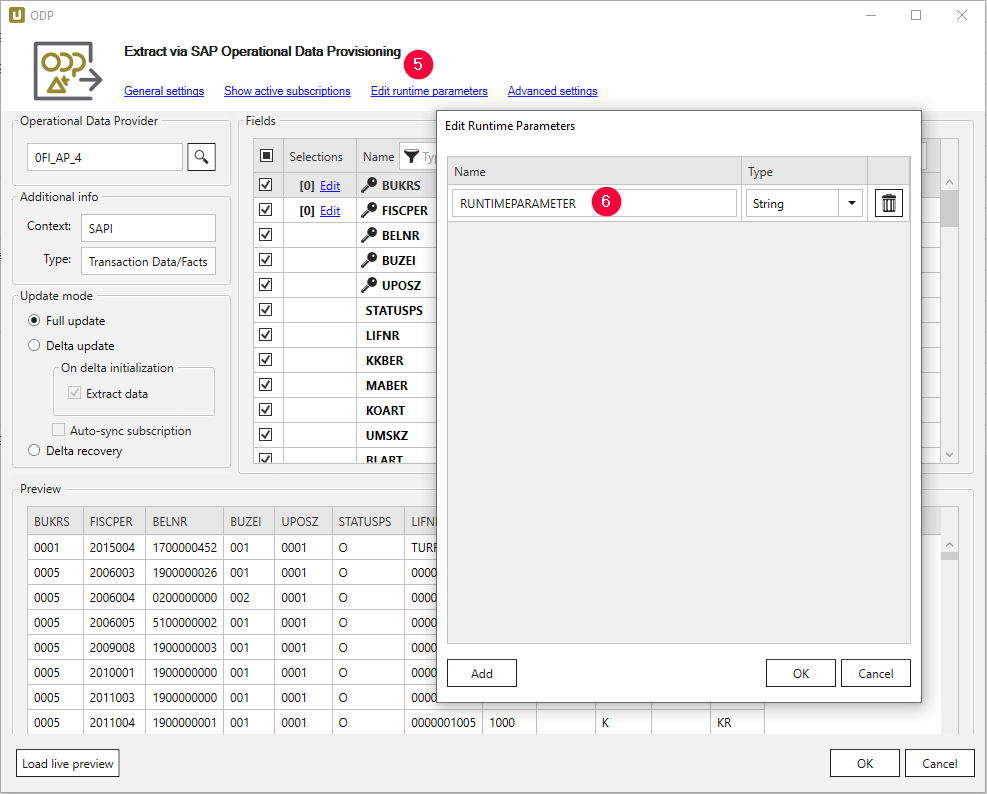
- Legen Sie den Laufzeitparameter RUNTIMEPARAMETER über die Schaltfläche Edit runtime parameter (5) an.
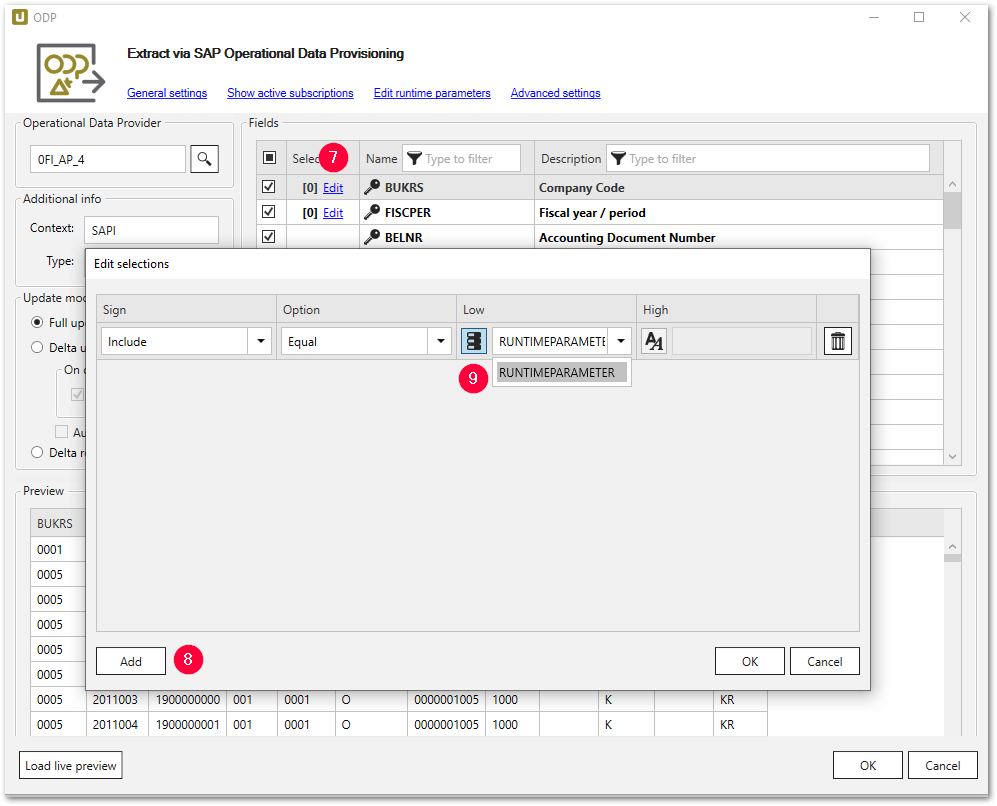
- Hinterlegen Sie den Laufzeitparameter über die Schaltfläche Edit in der Spalte Selections (7).
- Navigieren Sie zu den Destination Settings und wählen Sie im Abschnitt Preparation die Option Custom SQL. Klicken Sie auf Edit SQL.
- Wählen Sie im Dropdown-Menü die Option Drop & Create und klicken Sie auf [Generate Statement] (10).
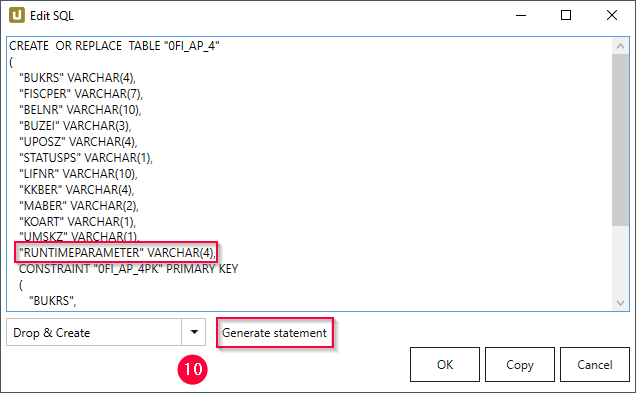
- Fügen Sie dem generierten Statement die folgende Zeile hinzu.
"RUNTIMEPARAMETER" VARCHAR(4), - Bestätigen Sie mit [OK].
- Im Abschnitt Row Processing werden die Spaltenwerte aus SAP in eine lokale CSV-Datei prozessiert.
Daher wird dieses SQL-Statement auf dem Standard Copy file to table belassen.
Zu diesem Zeitpunkt werden keine Daten aus dem SAP-Quellsystem, sondernNULLWerte in die neu angelegte Spalte RUNTIMEPARAMETER geschrieben. - Im Abschnitt Finalization werden die
NULLWerte mit der folgenden SQL-Anweisung des Laufzeitparameters RUNTIMEPARAMETER befüllt und durch den T-SQL BefehlUPDATEin die SQL-Zieltabelle geschrieben.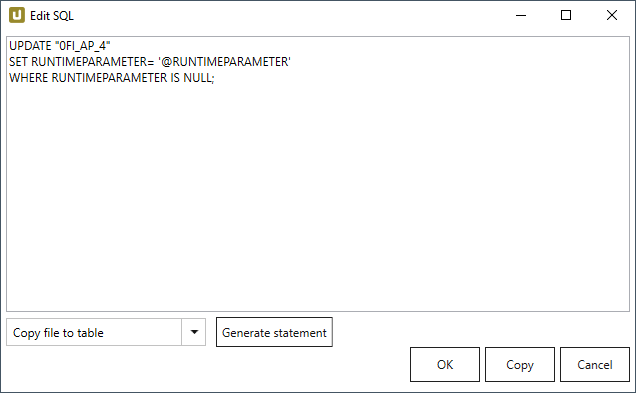
UPDATE "0FI_AP_4" SET RUNTIMEPARAMETER= '@RUNTIMEPARAMETER' WHERE RUNTIMEPARAMETER IS NULL; - Führen Sie die Extraktion über Run (11) aus und geben Sie einen geeigneten Wert für den Laufzeitparameter (12) an.
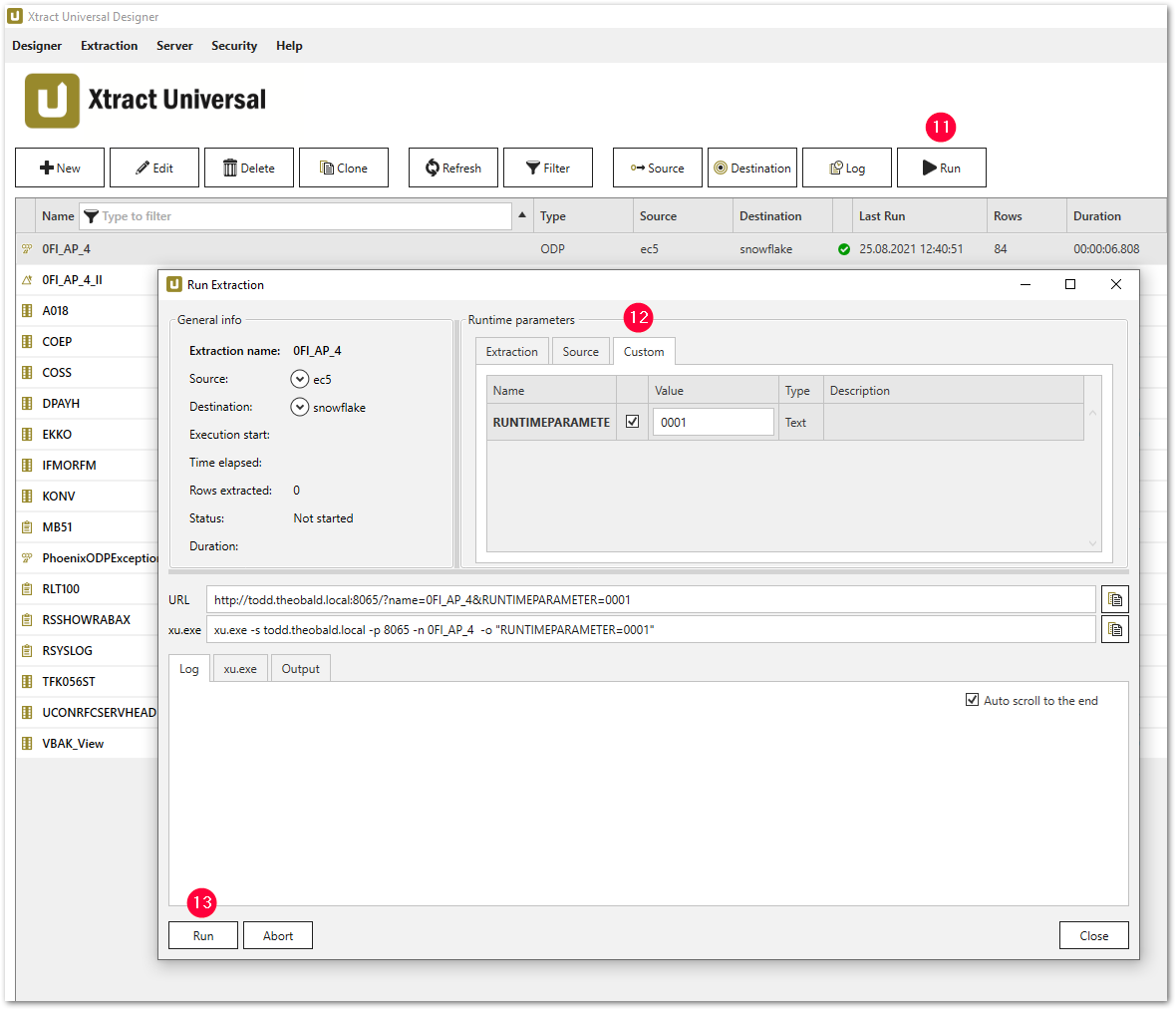
Ergebnis überprüfen #
Überprüfen Sie die Existenz der erweiterten Spalte RUNTIMEPARAMETER in der Snowflake Console der Tabelle 0FI_AP_4.