Die Destination Flat File erzeugt eine generische CSV-Datei.
Verbindung #
Eine Destination hinzufügen #
- Navigieren Sie im Hauptfenster des Designers zu Server > Manage Destinations. Das Fenster “Manage Destination” wird geöffnet.
- Klicken Sie auf [Add], um eine neue Destination hinzufügen. Das Fenster “Destination Details” wird geöffnet.
- Geben Sie einen Namen für die Destination ein.
- Wählen Sie den Destinationstyp aus dem Dropdown-Menü aus.
Destination Details - Destinationsdetails #
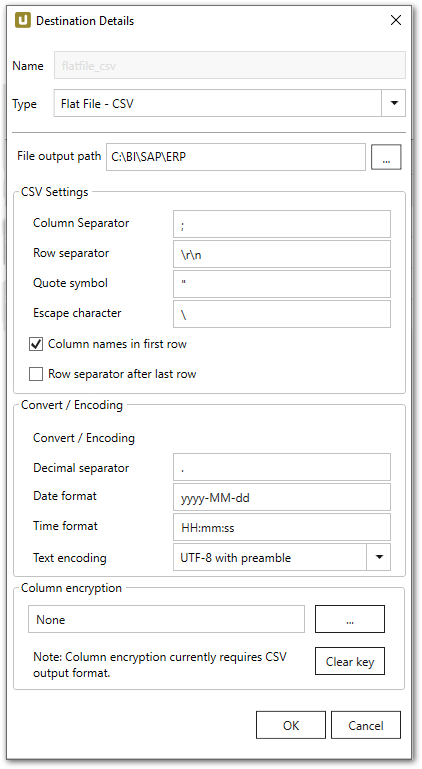
File output path
Geben Sie das Verzeichnis an, in dem die Flat Files gespeichert werden sollen.
Wenn das Verzeichnis nicht existiert, wird es erstellt.
Hinweis: Um Flat-Files auf ein Netzlaufwerk zu schreiben, muss Folgendes gegeben sein:
- Das Verzeichnis in File output path muss im UNC-Format angegeben sein, z.B. \\Server2\Share\Folder1.
- Der Benutzer, unter dem der Xtract Universal Dienst läuft, muss Schreibrechte auf das Verzeichnis haben.
CSV Settings #
Column seperator
Definiert, wie bei CSV zwei Spalten getrennt werden sollen.
Row separator
Definiert, wie bei CSV zwei Zeilen getrennt werden sollen.
Quote symbol (Feldbegrenzerzeichen)
Definiert, welches Zeichen zur Kapselung von Feldinformation verwendet wird. Eine Folge von Zeichen kann als “Quote Symbol” (Feldbegrenzerzeichen) verwendet werden.
Das Zitieren wird in den folgenden Szenarien angewendet:
- Das Spaltentrennzeichen ist Teil der Feldinformationen.
- Das Feldbegrenzerzeichen ist Teil der Feldinformationen.
- Das Zeilentrennzeichen ist Teil der Feldinformationen.
- Das Maskierungszeichen ist Teil der Feldinformationen.
Escape character (Maskierungszeichen)
Wenn das Maskierungseichen Teil der Feldinformationen ist, wird das entsprechende Feld, das dieses Zeichen enthält, mit dem Feldbegrenzerzeichen eingekapselt.
Das Standardmaskierungszeichen ist der Backslash ‘\’. Das Feld kann leer bleiben.
Column names in first row
Definiert, ob die erste Zeile die Spaltennamen enthält. Die Option ist standardmäßig gesetzt.
Row separator after last row
Definiert, ob die letzte Zeile einen Zeilenseparator enthält. Die Option ist standardmäßig gesetzt.
Convert / Encoding #
Decimal separator
Definiert den Dezimaltrenner für die Dezimalzahlen. Punkt (.) ist der Standard-Wert.
Date format
Definiert ein benutzerdefiniertes Datumsformat (z.B. YYYY-MM-DD oder MM/DD/YYYY), um gültige SAP-Datumswerte (YYYYMMDD) zu formatieren. Default ist YYYY-MM-DD.
Time format
Definiert ein benutzerdefiniertes Zeitformat (z.B. HH:MM:SS oder HH-MM-SS), um gültige SAP-Zeitwerte (HHMMSS) zu formatieren. Default ist HH:MM:SS.
Text Encoding
Definiert die Zeichenketten-Kodierung.
Column encryption #
Allgemeines
Sie können Daten sowohl verschlüsselt als auch unverschlüsselt speichern. Die “Column Encryption” (Spalten-Verschlüsselung) ermöglicht Ihnen eine Verschlüsselung der Spalten bevor die extrahierten Daten in die Destination hochgeladen werden. Dadurch kann sichergestellt werden, dass sensible Informationen geschützt sind.
Diese Funktion unterstützt außerdem wahlfreien Zugriff, d.h. dass Daten von jedem beliebigen Startpunkt aus entschlüsselt werden können. Da wahlfreier Zugriff einen erheblichen Overhead verursacht, wird empfohlen die Spalten-Verschlüsselung nicht auf den gesamten Datensatz anzuwenden.
Weiteres Vorgehen
Hinweis: Der Benutzer muss einen öffentlichem RSA Schlüssel zur Verfügung stellen.
-
Wählen Sie die zu verschlüsselnden Spalten unter Extraction settings > General settings > Encryption aus.
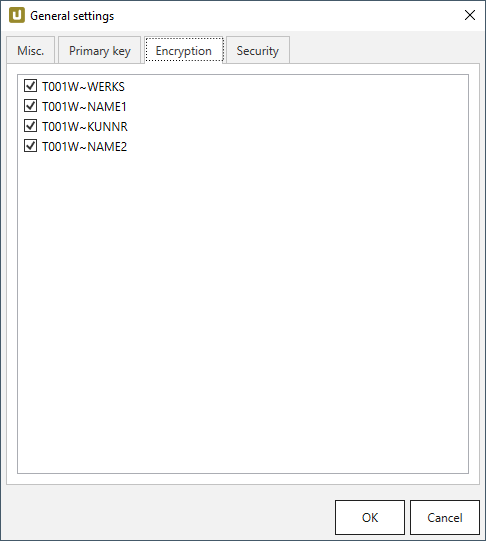
-
Stellen Sie sicher, dass die Enable column level encryption Checkbox unter Extraction settings > General settings > Misc. ausgewählt ist.
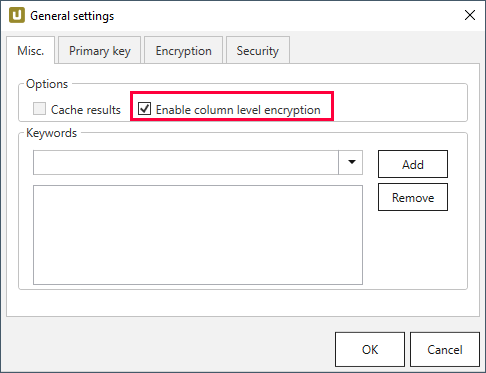
-
Klicken Sie unter Destination Details > Column Encryption auf […], um den öffentlichen Schlüssel als .xml-Datei zu importieren.
-
Führen Sie die Extraktion aus.
-
Warten Sie bis XtractUniversal die verschlüsselten Daten und die “metadata.json” Datei auf die Destination hochgeladen hat.
-
Triggern Sie manuell oder automatisch Ihre Entschlüsselungsroutine.
Entschlüsselung
Die Entschlüsselung ist abhängig von der Destination. Beispiele für eine Implementierung mit Azure Storage, AWS S3 und lokalen CVS Dateien finden Sie in GitHub. Die Beispiele beinhalten sowohl Kryptografie als auch ein Interface, um “metadata.json” und CSV Daten zu lesen. Der kryptografische Aspekt ist Open Source, das Interface nicht.
Technische Informationen
Die Verschlüsselung ist als Hybridverschlüsselung implementiert.
Das bedeutet, dass ein zufälliger AES Session Key (Sitzungsschlüssel) generiert wird sobald eine Extraktion ausgeführt wird.
Die Daten werden dann über den AES-GCM Algorithmus in Kombination mit dem Session Key verschlüsselt.
Die Implementierung verwendet die empfohlene Länge von 96 bits für den Initialisierungsvektor (IV).
Um den wahlfreien Datenzugriff zu garantieren, erhält jede Zelle seinen eigenen IV/nonce und einen Message Authentication Code (MAC).
Der MAC ist ein Authentifizierungstoken in GCM.
Im daraus resultierenden Datenset sind die Zellen wie folgt verschlüsselt:
IV|ciphertext|MAC
mit IV als 7-Bit Integer. Der Session Key wird daraufhin mit dem öffentlichen RSA Schlüssel des Benutzers verschlüsselt und zusammen mit einer Liste verschlüsselter Spalten und Formatinformation als “metadata.json” Datei auf die Destination hochgeladen.
Einstellungen #
Destination Settings öffnen #
- Eine bestehende Extraktion anlegen oder auswählen, siehe Erste Schritte mit Xtract Universal.
- Klicken Sie auf [Destination]. Das Fenster “Destination Settings” wird geöffnet.
Die folgenden Einstellungen können für die Destination definiert werden.
Destination Settings - Destinationseinstellungen #
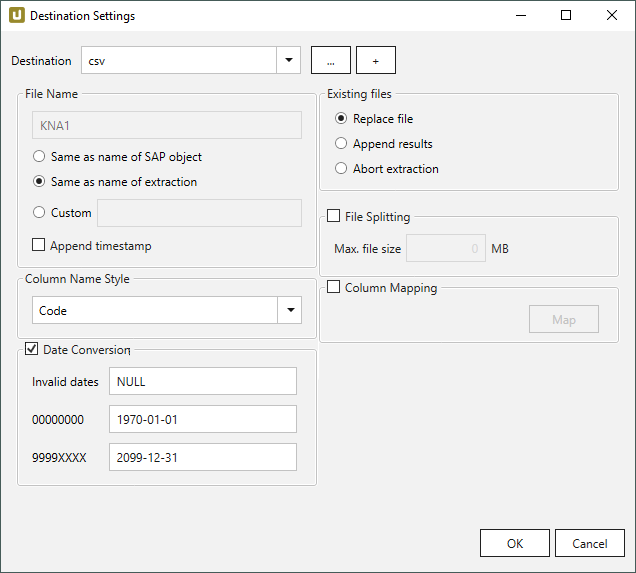
File Name #
File Name bestimmt den Namen der Zieltabelle. Sie haben die folgenden Optionen:
- Same as name of SAP object: Name des SAP-Objekts übernehmen
- Same as name of extraction: Name der Extraktion übernehmen
- Custom: Hier können Sie einen eigenen Namen definieren
- Append timestamp: fügt den Zeitstempel im UTC-Format (_YYYY_MM_DD_hh_mm_ss_fff) dem Dateinamen der Extraktion hinzu.
Skript-Ausdrücke als dynamische Dateinamen
Skript-Ausdrücke können für die Generierung eines dynamischen Dateinamens verwendet werden. Dadurch kann ein Name generiert werden, der sich aus den Eigenschaften einer Extraktion zusammensetzt, z.B. Extraktionsname, SAP-Quellobjekt. Unterstützt werden Skript-Ausdrücke, die auf .NET basieren, sowie folgende XU-spezifische Skript-Ausdrücke:
| Eingabe | Beschreibung |
|---|---|
#{Source.Name}# |
Name der SAP Quelle. |
#{Extraction.ExtractionName}# |
Name der Extraktion. Wenn die Extraktion Teil einer Extraktionsgruppe ist, geben Sie den Namen der Extraktionsgruppe vor dem Namen der Extraktion ein. Trennen Sie Gruppen mit ‘,’, z.B., Tables,KNA1, S4HANA,Tables,KNA1. |
#{Extraction.Type}# |
Extraktionstyp (Table, ODP, DeltaQ, etc.). |
#{Extraction.SapObjectName}# |
Name des SAP Objekts, von dem die Extraktion Daten extrahiert. |
#{Extraction.Timestamp}# |
Zeitstempel der Extraktion. |
#{Extraction.SapObjectName.TrimStart("/".ToCharArray())}# |
Entfernt einen führenden Schrägstrich, z.B. wird aus /BIO/TMATERIAL dann BIO/TMATERIAL, damit kein leeres Verzeichnis angelegt wird. |
#{Extraction.SapObjectName.Replace('/', '_')}# |
Entfernt alle Schrägstriche eines SAP Objekts, z.B. wird aus /BIO/TMATERIAL dann _BIO_TMATERIAL. Dadurch wird verhindert, dass die Schrägstriche innerhalb des Namens des SAP Objekts, nicht als Verzeichnistrenner interpretiert werden. |
#{Extraction.Context}# |
Nur für ODP Extraktionen: Kontext des ODP Objekts (SAPI, ABAP_CDS, etc.). |
#{Extraction.Fields["[NameSelectionFiels]"].Selections[0].Value}# |
Nur für ODP Extraktionen: Eingabewert einer definierten Selektion / eines Filter. |
#{Odp.UpdateMode}# |
Nur für ODP Extraktionen: Load-Verfahren (Delta, Full, Repeat) der Extraktion. |
#{TableExtraction.WhereClause}# |
Nur für Table Extraktionen: WHERE-Bedingung der Extraktion. |
Column Name Style #
Definiert den Spaltennamen. Folgende Optionen sind verfügbar:
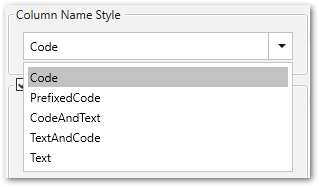
- Code: Der technische Spaltenname aus SAP wird als Spaltenname verwendet, z.B. MAKTX
- PrefixedCode: Der technische Name der Tabelle wird mit dem Tilde-Zeichen und dem entsprechenden Spaltennamen verbunden, z. B. MAKT~MAKTX.
- CodeAndText: Der technische Name und die Beschreibung der Spalte aus SAP mit einem Unterstrich verbunden werden als Spaltennamen verwendet, z.B. MAKTX_Material Description (Short Text).
- TextAndCode: Die Beschreibung und der technische Name der Spalte SAP mit einem Unterstrich verbunden werden als Spaltennamen verwendet, z.B. Material Description (Short Text)_MAKTX.
- Text: Die Beschreibung aus SAP wird als Spaltenname verwendet, z.B. Material Description (Short Text).
Date conversion #
Convert date strings
Konvertiert die Zeichenabfolge des SAP-Datums (YYYYMMDD, z.B. 19900101) zu einem formatierten Datum (YYYY-MM-DD, z.B. 1990-01-01). Im Datenziel hat das SAP-Datum keinen String-Datentyp sondern einen echten Datumstyp.
Convert invalid dates to
Falls ein SAP-Datum nicht in ein gültiges Datumsformat konvertiert werden kann, wird das ungültige Datum zu dem eingegebenen Wert konvertiert. NULL wird als Wert unterstützt.
Bei der Konvertierung eines ungültigen SAP-Datums werden zuerst die beiden Sonderfälle 00000000 und 9999XXXX überprüft.
Convert 00000000 to
Konvertiert das SAP-Datum 00000000 zu dem eingegebenen Wert.
Convert 9999XXXX to
Konvertiert das SAP-Datum 9999XXXX zu dem eingegebenen Wert.
Existing files #
Replace file: eine vorhandene Zieldatei wird überschrieben.
Append results: Daten werden in einer bereits existierenden Zieldatei ergänzt. Siehe auch Column Mapping.
Abort extraction: Der Prozess wird abgebrochen, falls eine Zieldatei bereits existiert.
File Splitting #
File Splitting
Schreibt die Extraktionsdaten einer einzelnen Extraktion in mehrere Dateien.
Dabei wird an jeden Dateinamen _part[nnn] angehägt.
Max. file size
Geben Sie die Maximalgröße der einzelnen Dateien ein, die abgelegt werden sollen.
Note: Die Option Max. file size wird nicht von gzip-Dateien unterstützt. Die Größe von durch gzip-Verfahren komprimierten Dateien kann nicht im Voraus bestimmt werden.
Column Mapping #
Verwenden Sie Column Mapping, wenn Sie Daten in einer Zieldatei oder Zieleinheit ergänzen und Spalten manuell zugewiesen werden müssen.
Das kann der Fall sein, wenn Sie Daten von zwei oder mehr Extraktionen in eine Zieldatei schreiben, in der sich die Spaltennamen von den Spaltennamen der Extraktionen unterscheiden.
Hinweis: Die Spaltennamen in der Extraktion und der Zieldatei müssen einzigartig sein. Wenn doppelte Spaltennamen detektiert werden, öffnet sich eine entsprechende Fehlermeldung. Die Spaltennamen müssen korrigiert werden, bevor mit der Spaltenzuweisung begonnen werden kann.
- Wenn Sie Daten in flache Dateien schreiben, muss folgendes gewährleistet sein:
a) der Server, auf dem der Xract Universal Service läuft und der Designer müssen beide Zugriff auf die Zieldatei haben.
b) der angegebene Pfad und Dateiname muss mit dem Pfad und dem Namen der Zieldatei überein stimmen.
c) der Column Name Style der Extraktion muss mit der Zieldatei überein stimmen. - Wählen Sie im Abschnitt Existing Files die Option Append results aus.
- Klicken Sie auf [Map], um Spalten zuzuweisen. Das Fenster “Column Mapping” öffnet sich.
Unter Destination Column werden die Spaltennamen aus dem Header der Zieldatei angezeigt. Unter Not Mapped können Spalten markiert werden, bei denen keine Zuweisung erfolgen soll. Unter Source Columns können SAP-Spalten zugewiesen werden.
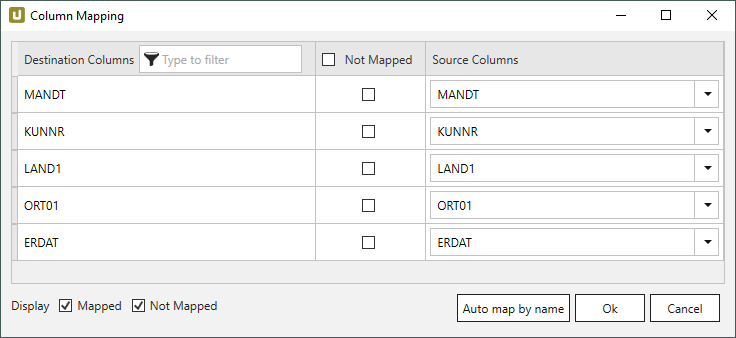
- a) Wenn die Spaltennamen in der Zieldatei dieselben sind wie in SAP, klicken Sie auf [Auto map by name].
b) Wenn die Spaltennamen nicht übereinstimmen, weisen Sie SAP-Spalten manuell über das entsprechende Dropdown-Menü zu.
c) Wenn einer Spalte nichts zugewiesen werden soll, markieren Sie die entsprechende Checkbox unter Not Mapped. - Klicken Sie auf [OK], um Ihre Auswahl zu bestätigen.
Wenn Sie die Extraktion ausführen, wird die Zieldatei oder Zieleinheit entsprechend Ihrer Spaltenzuweisung erweitert.
Tipp: Wenn sich eine Fehlermeldung öffnet, klicken Sie auf [Show More], um eine Beschreibung der Fehlerursache zu finden.