Der folgende Abschnitt behandelt das Laden der SAP-Extraktionsdaten in eine EXASolution-Zieldatenbank.
Voraussetzungen #
Ab der Version Xtract Universal 4.2.26.0 wird der Exasol ADO.Net Treiber ExaDataProvider mit dem Setup von Xtract Universal ausgeliefert. Es sind keine zusätzlichen Installationen erforderlich, um die Destination Exasol-Datenbank zu verwenden.
Verbindung #
Eine Destination hinzufügen #
- Navigieren Sie im Hauptfenster des Designers zu Server > Manage Destinations. Das Fenster “Manage Destination” wird geöffnet.
- Klicken Sie auf [Add], um eine neue Destination hinzufügen. Das Fenster “Destination Details” wird geöffnet.
- Geben Sie einen Namen für die Destination ein.
- Wählen Sie den Destinationstyp aus dem Dropdown-Menü aus.
Destination Details #
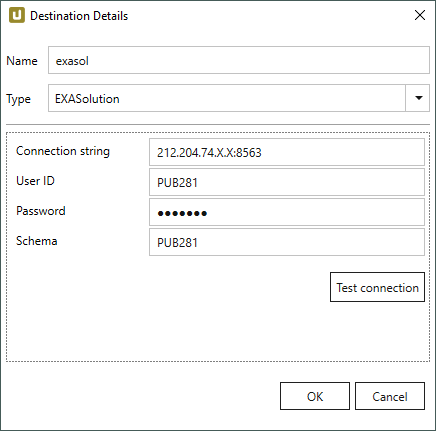
Connection string
Name bzw. IP des Datenbankservers und die Portnummer eingeben.
User Id / Password
Name und Passwort des Datenbank-Benutzers eingeben.
Database Name
Name der Datenbank.
Schema
Schema der Datenbank eingeben.
Test Connection
Klicken Sie auf die Schaltfläche, um die Verbindung zu testen.
Einstellungen #
Destination Settings öffnen #
- Eine bestehende Extraktion anlegen oder auswählen, siehe Erste Schritte mit Xtract Universal.
- Klicken Sie auf [Destination]. Das Fenster “Destination Settings” wird geöffnet.
Die folgenden Einstellungen können für die Destination definiert werden.
Destination Settings - Destinationseinstellungen #
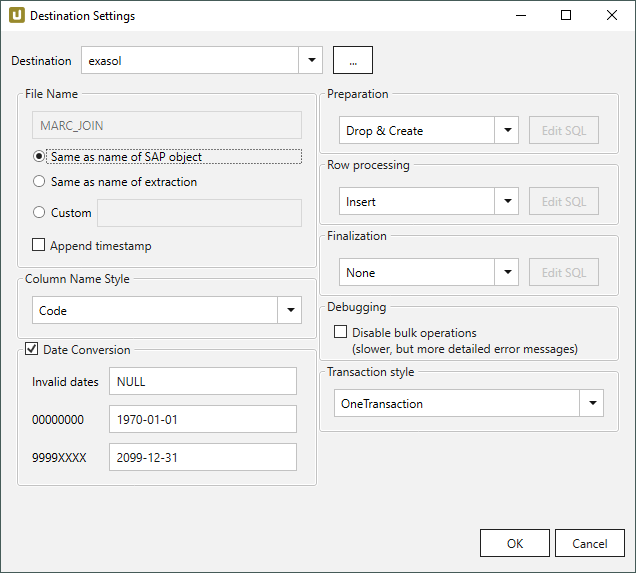
File Name #
File Name bestimmt den Namen der Zieltabelle. Sie haben die folgenden Optionen:
- Same as name of SAP object: Name des SAP-Objekts übernehmen
- Same as name of extraction: Name der Extraktion übernehmen
- Custom: Hier können Sie einen eigenen Namen definieren
- Append timestamp: fügt den Zeitstempel im UTC-Format (_YYYY_MM_DD_hh_mm_ss_fff) dem Dateinamen der Extraktion hinzu.
Skript-Ausdrücke als dynamische Dateinamen
Skript-Ausdrücke können für die Generierung eines dynamischen Dateinamens verwendet werden. Dadurch kann ein Name generiert werden, der sich aus den Eigenschaften einer Extraktion zusammensetzt, z.B. Extraktionsname, SAP-Quellobjekt. Unterstützt werden Skript-Ausdrücke, die auf .NET basieren, sowie folgende XU-spezifische Skript-Ausdrücke:
| Eingabe | Beschreibung |
|---|---|
#{Source.Name}# |
Name der SAP Quelle. |
#{Extraction.ExtractionName}# |
Name der Extraktion. Wenn die Extraktion Teil einer Extraktionsgruppe ist, geben Sie den Namen der Extraktionsgruppe vor dem Namen der Extraktion ein. Trennen Sie Gruppen mit ‘,’, z.B., Tables,KNA1, S4HANA,Tables,KNA1. |
#{Extraction.Type}# |
Extraktionstyp (Table, ODP, DeltaQ, etc.). |
#{Extraction.SapObjectName}# |
Name des SAP Objekts, von dem die Extraktion Daten extrahiert. |
#{Extraction.Timestamp}# |
Zeitstempel der Extraktion. |
#{Extraction.SapObjectName.TrimStart("/".ToCharArray())}# |
Entfernt einen führenden Schrägstrich, z.B. wird aus /BIO/TMATERIAL dann BIO/TMATERIAL, damit kein leeres Verzeichnis angelegt wird. |
#{Extraction.SapObjectName.Replace('/', '_')}# |
Entfernt alle Schrägstriche eines SAP Objekts, z.B. wird aus /BIO/TMATERIAL dann _BIO_TMATERIAL. Dadurch wird verhindert, dass die Schrägstriche innerhalb des Namens des SAP Objekts, nicht als Verzeichnistrenner interpretiert werden. |
#{Extraction.Context}# |
Nur für ODP Extraktionen: Kontext des ODP Objekts (SAPI, ABAP_CDS, etc.). |
#{Extraction.Fields["[NameSelectionFiels]"].Selections[0].Value}# |
Nur für ODP Extraktionen: Eingabewert einer definierten Selektion / eines Filter. |
#{Odp.UpdateMode}# |
Nur für ODP Extraktionen: Load-Verfahren (Delta, Full, Repeat) der Extraktion. |
#{TableExtraction.WhereClause}# |
Nur für Table Extraktionen: WHERE-Bedingung der Extraktion. |
Column Name Style #
Definiert den Spaltennamen. Folgende Optionen sind verfügbar:
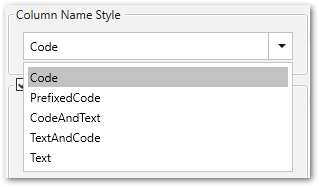
- Code: Der technische Spaltenname aus SAP wird als Spaltenname verwendet, z.B. MAKTX
- PrefixedCode: Der technische Name der Tabelle wird mit dem Tilde-Zeichen und dem entsprechenden Spaltennamen verbunden, z. B. MAKT~MAKTX.
- CodeAndText: Der technische Name und die Beschreibung der Spalte aus SAP mit einem Unterstrich verbunden werden als Spaltennamen verwendet, z.B. MAKTX_Material Description (Short Text).
- TextAndCode: Die Beschreibung und der technische Name der Spalte SAP mit einem Unterstrich verbunden werden als Spaltennamen verwendet, z.B. Material Description (Short Text)_MAKTX.
- Text: Die Beschreibung aus SAP wird als Spaltenname verwendet, z.B. Material Description (Short Text).
Date conversion #
Convert date strings
Konvertiert die Zeichenabfolge des SAP-Datums (YYYYMMDD, z.B. 19900101) zu einem formatierten Datum (YYYY-MM-DD, z.B. 1990-01-01). Im Datenziel hat das SAP-Datum keinen String-Datentyp sondern einen echten Datumstyp.
Convert invalid dates to
Falls ein SAP-Datum nicht in ein gültiges Datumsformat konvertiert werden kann, wird das ungültige Datum zu dem eingegebenen Wert konvertiert. NULL wird als Wert unterstützt.
Bei der Konvertierung eines ungültigen SAP-Datums werden zuerst die beiden Sonderfälle 00000000 und 9999XXXX überprüft.
Convert 00000000 to
Konvertiert das SAP-Datum 00000000 zu dem eingegebenen Wert.
Convert 9999XXXX to
Konvertiert das SAP-Datum 9999XXXX zu dem eingegebenen Wert.
Preparation - SQL Anweisungen #
Definiert die Aktion auf der Zieldatenbank, bevor die Daten in die Zieltabelle eingefügt werden.
- Drop & Create: Tabelle entfernen falls vorhanden und neu anlegen (Default).
- Truncate Or Create: Tabelle entleeren falls vorhanden, sonst anlegen.
- Create If Not Exists: Tabelle anlegen falls nicht vorhanden.
- Prepare Merge: bereitet den Merge-Prozess vor und erstellt z.B. eine temporäre Staging-Tabelle. Für weitere Infos siehe Daten Mergen.
- None: keine Aktion
- Custom SQL: Hier können Sie eigenes Skript definieren. Siehe den unteren Abschnitt Custom SQL.
Wollen Sie im ersten Schritt nur die Tabelle anlegen und keine Daten einfügen, dann haben Sie zwei Möglichkeiten:
- Sie kopieren das SQL-Statement und führen es direkt auf der Zieldaten-Datenbank aus.
- Sie wählen die Option None für Row Processing und führen die Extraktion aus.
Nachdem die Tabelle angelegt ist, bleibt es Ihnen überlassen, die Tabellendefinition zu ändern, indem Sie bspw. entsprechende Schlüsselfelder und Indizes bzw. zusätzliche Felder anlegen.
Row Processing - SQL Anweisungen #
Definiert, wie die Daten in die Zieltabelle eingefügt werden.
- Insert: Datensätze einfügen (Default).
- Fill merge staging table: Datensätze in die Staging-Tabelle einfügen.
- None: keine Aktion.
- Custom SQL: Hier können Sie eigenes Skript definieren. Siehe den unteren Abschnitt Custom SQL.
- Merge (deprecated): Diese Option ist veraltet. Bitte nutzen Sie die Option Fill merge staging table und prüfen Sie den Abschnitt Über Merging.
Finalization - SQL Anweisungen #
Definiert die Aktion auf der Zieldatenbank, nachdem die Daten in die Zieltabelle erfolgreich eingefügt werden.
- Finalize Merge: schließt den Merge-Prozess ab und löscht z.B. die temporäre Staging-Tabelle. Für weitere Infos siehe Abschnitt Über Merging.
- None: keine Aktion (Default).
- Custom SQL: Hier können Sie eigenes Skript definieren. Siehe den unteren Abschnitt Custom SQL.
Über Merging
Die Zusammenführung gewährleistet eine Deltaverarbeitung: neue Datensätze werden in die Datenbank eingefügt und/oder bestehende Datensätze werden aktualisiert. Mehr Details im Abschnitt Daten zusammenführen (mergen).
Custom SQL #
Die Option Custom SQL ermöglicht die Erstellung benutzerdefinierter SQL- oder Skriptausdrücke. Vorhandene SQL-Befehle können als Vorlagen verwendet werden:
- Wählen Sie im Unterabschnitt z.B. Preparation die Option Custom SQL (1) aus der Dropdown-Liste.
- Klicken Sie auf [Edit SQL]. Der Dialog “Edit SQL” wird geöffnet.
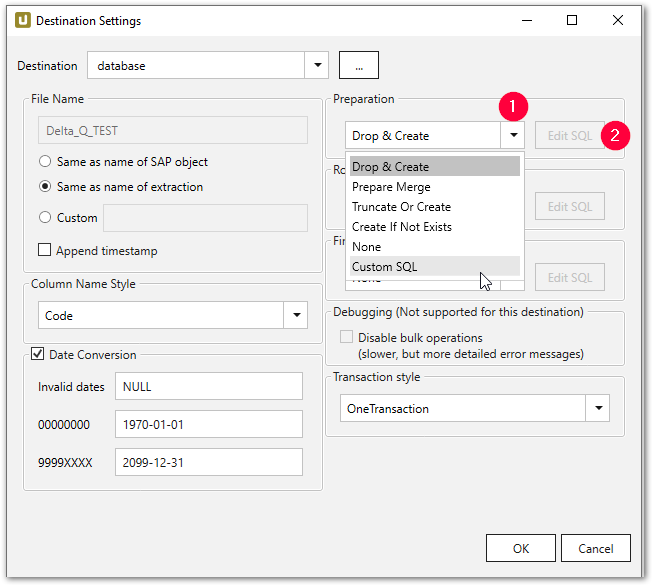
- Navigieren Sie zum Dropdown-Menü und wählen Sie einen vorhandenen Befehl (3).
- Klicken Sie auf [Generate Statement]. Eine neue Anweisung wird generiert.
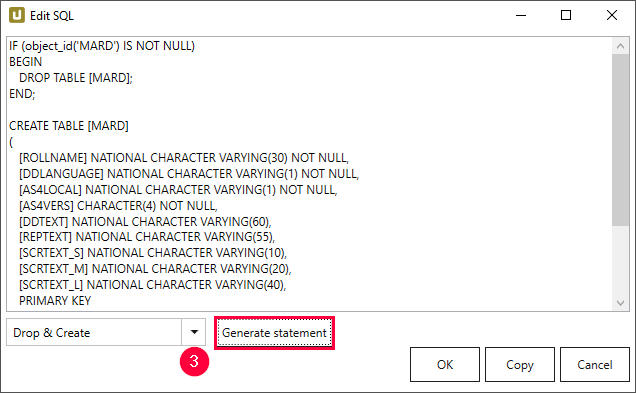
- Klicken Sie auf [Copy] um die Anweisung in den Zwischenspeicher zu kopieren.
- Klicken Sie zur Bestätigung auf [OK].
Einzelheiten zu vordefinierten Ausdrücken finden Sie im Microsoft SQL Server Beispiel.
Note: Der benutzerdefinierte SQL-Code wird für SQL Server-Destinationen verwendet. Um den benutzerdefinierten SQL-Code für andere Datenbank-Destinationen zu verwenden, ist eine syntaktische Anpassung des Codes erforderlich.
Vorlagen
Sie können eigene SQL-Ausdrücke schreiben und haben damit die Möglichkeit, das Laden der Daten an Ihre Bedürfnisse anzupassen.
Darüber hinaus können Sie z.B. auch auf der Datenbank bestehende “Stored Procedures” ausführen.
Dafür können Sie die vordefinierten SQL-Vorlagen der folgenden Phasen verwenden:
- Preparation (z.B. Drop & Create oder Create if Not Exists)
- Row Processing (z.B. Insert oder Merge) und
- Finalization
Skript-Ausdrücke verwenden
Sie können Skript-Ausdrücke für die Custom-SQL-Befehle verwenden.
Die folgenden XU-spezifischen benutzerdefinierten Skript-Ausdrücke werden unterstützt:
| Eingabe | Beschreibung |
|---|---|
#{Extraction.TableName }# |
Name der Datenbanktabelle, in die die extrahierten Daten geschrieben werden |
#{Extraction.RowsCount }# |
Anzahl der extrahierten Zeilen |
#{Extraction.RunState}# |
Status der Extraktion (Running, FinishedNoErrors, FinishedErrors) |
#{(int)Extraction.RunState}# |
Status der Extraktion als Return-Code (2 = Running, 3 = FinishedNoErrors, 4 = FinishedErrors) |
#{Extraction.Timestamp}# |
Zeitstempel der Extraktion |
bool ExistsTable(string tableName) |
Prüft, ob die Tabelle auf der Datenbank-Destination existiert. |
Für mehr Informationen zu Skript-Ausdrücken, siehe Skript-Ausdrücke.
SQL-Skript
#{
iif
(
ExistsTable("MAKT"),
"TRUNCATE TABLE \"MAKT\";",
"
CREATE TABLE \"MAKT\"(
\"MATNR\" VARCHAR(18),
\"SPRAS\" VARCHAR(2),
\"MAKTX\" VARCHAR(40));
"
)
}#Tipp: Der Befehl ExistsTable(tableName) ermöglicht die Überprüfung des Vorhandenseins einer Tabelle in einer Datenbank.
Debugging #
Warnung! Performance-Verlust (Leistungseinbuße)! Die Performance sinkt, wenn Bulk Insert deaktiviert ist. Deaktivieren Sie den Bulk Insert nur wenn es notwendig ist, z.B. auf Anfrage des Support-Teams.
Durch das Anhaken der Checkbox Disable bulk operations wird der standardmäßige Bulk Insert beim Schreiben auf die Datenbank deaktiviert.
Diese Option ermöglicht eine detaillierte Fehleranalyse, falls bestimmte Datenzeilen nicht auf der Datenbank persistiert werden können. Mögliche Ursachen für dieses Verhalten können fehlerhafte Werte im hinterlegten Datentyp sein.
Das Debugging sollte nach der erfolgreichen Fehleranalyse wieder deaktiviert werden, da ansonsten die Performance der Datenbank-Schreibprozesse dauerhaft niedrig bleibt.
Verwendung von Custom SQL
Hinweis: Bulk Operations werden beim Verwenden von Custom SQL Anweisungen (z.B. bei Row Processing) nicht unterstützt. Dies führt zu Performance-Verlust (Leistungseinbußen).
Tip: Um die Performance beim Verwenden von Custom SQL Anweisungen zu steigern, wird empfohlen die Custom-Verarbeitung im Finalization-Schritt zu verwenden.
Transaction style #
Hinweis: Je nach Destination variieren die verfügbaren Optionen für Transaction Style.
One Transaction
Preparation, Row Processing und Finalization werden in einer einer einzigen Transaktion ausgeführt.
Vorteil: sauberer Rollback aller Änderungen.
Nachteil: ggf. umfangreiches Locking während der gesamten Extraktionsdauer.
Es ist empfohlen, One Transaction nur in Kombination mit DML-Befehlen zu verwenden, z. B. „truncate table“ und „insert“.
Durch die Verwendung von DDL-Befehlen wird die aktive Transaktion festgeschrieben, was zu Rollback-Problemen für die Schritte nach dem DDL-Befehl führt.
Beispiel: Wenn im Vorbereitungsschritt eine Tabelle erstellt wird, wird die geöffnete „OneTransaction“ festgeschrieben und ein Rollback in den nächsten Schritten wird nicht korrekt durchgeführt.
Weitere Informationen finden Sie unter Snowflake Documentation: DDL Statements.
Three Transactions
Prepare, Row Processing und Finalization werden jeweils in einer eigenen Transaktion ausgeführt.
Vorteil: sauberer Rollback der einzelnen Abschnitte, evtl. kürzere Locking-Phasen als bei One Transaction (z. B. bei DDL in Preparation wird die gesamte DB nur bei Preparation gelockt und nicht für die gesamte Extraktionsdauer)
Nachteil: Kein Rollback von vorangegangen Schritt möglich (Fehler im Row Processing rollt nur Änderungen aus Row Processing zurück, nicht aus Preparation).
RowProcessingOnly
Nur Row Processing wird in einer Transaktion ausgeführt. Preparation und Finalization ohne explizite Transaktion (implizite commits).
Vorteil: DDL in Perparation und Finalization bei DBMS, die kein DDL in expliziten Transaktionen zulassen (z. B. AzureDWH).
Nachteil: Kein Rollback von Preparation/Finalization.
No Transaction
Keine expliziten Transaktionen.
Vorteil: Keine Transaktionsverwaltung durch DBMS benötigt (Locking, DB-Transaktionslog, etc.). Dadurch kein Locking und evtl. Performanzvorteile.
Nachteil: Kein Rollback.
Daten Mergen #
Das folgende Beispiel zeigt die Aktualisierung der vorhandenen Datensätze in einer Datenbank durch Ausführen einer Extraktion. Dabei geht es um Zusammenzuführen (Merge) der Daten, d.h. z.B. den Wert eines Feldes zu ändern oder eine neue Datenzeile einzufügen oder eine vorhandene zu aktualisieren.
Alternativ zum Zusammenführen (Merge) können die Datensätze durch einen “Full Load” aktualisiert werden. Das Full-Load-Verfahren ist weniger effizient und performant.
Voraussetzung für das Zusammenführen (Merge) ist eine Tabelle mit vorhandenen Daten, in welche neue Daten zusammengeführt werden sollen.
Im Idealfall wird die Tabelle mit den vorhandenen Daten im initialen Lauf mit der dazugehörigen Option Preparation erstellt und durch die Option Insert in Row Processing befüllt.
Warnung! Fehlerhaftes Zusammenführen
Ein Primärschlüssel ist eine Voraussetzung für einen Merge-Befehl. Wenn kein Primärschlüssel gesetzt ist, läuft der Zusammenführungsbefehl in einen Fehler.
Erstellen Sie einen entsprechenden Primärschlüssel in General Settings, um den Merge-Befehl ausführen zu können.
Aktualisierter Datensatz in SAP #
Ein Feldwert innerhalb einer SAP-Tabelle wird aktualisiert. Mit einem Merge-Befehl wird der aktualisierte Wert in die Zieldatenbanktabelle geschrieben.
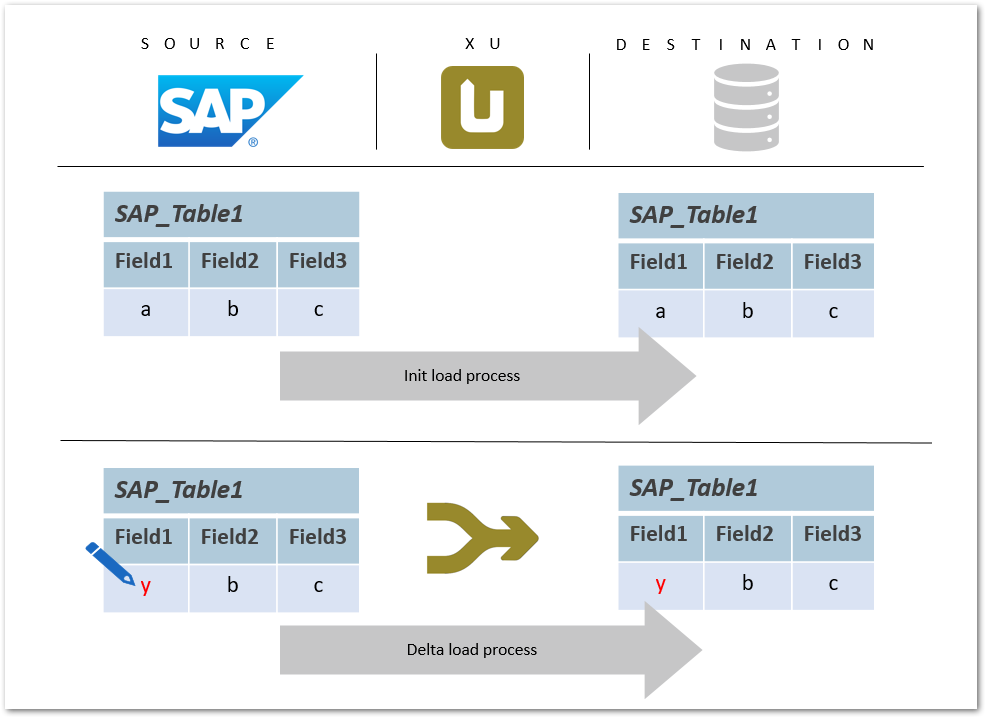
Der Merge-Befehl gewährleistet eine Deltaverarbeitung: neue Datensätze werden in die Datenbank eingefügt und/oder bestehende Datensätze aktualisiert.
Merge-Befehl in Xtract Universal #
Der Merge-Prozess wird mit Hilfe einer Staging-Tabelle durchgeführt und erfolgt in drei Schritten. Im ersten Schritt wird eine temporäre Tabelle angelegt, in die die Daten im zweiten Schritt eingefügt werden. Im dritten Schritt wird die temporäre Tabelle mit der Zieltabelle zusammengeführt und anschließend wird die temporäre Tabelle gelöscht.
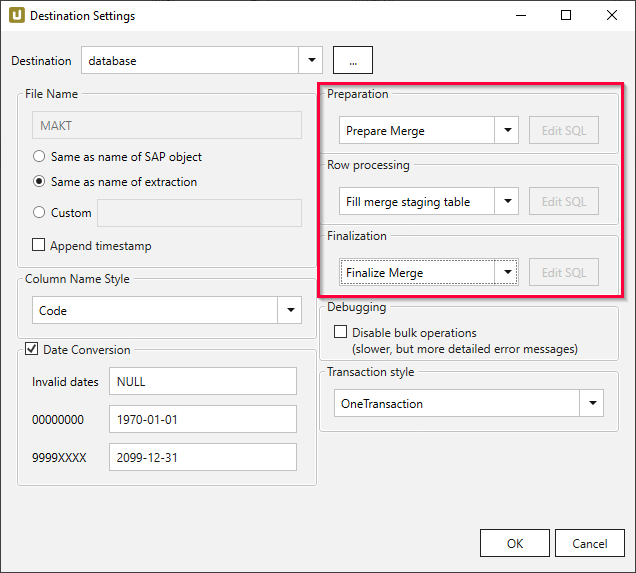
- Wählen Sie im Hauptfenster des Designers die entsprechende Extraktion aus und klicken Sie auf [Destination]. Das Fenster “Destination Settings” wird geöffnet.
- Stellen Sie sicher, dass Sie die passende Destination wählen: eine Datenbankdestination.
- Navigieren Sie zum rechten Teil des Fensters “Destination Settings” und wenden Sie die folgenden Einstellungen an:
- Preparation: Prepare Merge, um eine temporäre Staging-Tabelle zu erstellen
- Row Processing: Fill merge staging table, um die Staging-Tabelle mit Dateien zu befüllen
- Finalization: Finalize Merge, um die Staging-Tabelle mit der Zieldatenbanktabelle zusammenzuführen und anschließend die Staging-Tabelle zu löschen.
Weitere Informationen über die aktualisierten Felder finden Sie in der SQL-Anweisung (nur Custom SQL).
Es ist möglich, die SQL-Anweisung bei Bedarf zu bearbeiten, z.B. bestimmte Spalten von der Aktualisierung auszuschließen.
Felder, die nicht in der SQL-Anweisung erscheinen, sind von den Änderungen nicht betroffen.