Der folgende Abschnitt behandelt das Laden der SAP-Extraktionsdaten in den Cloud-Speicher Azure Storage.
Voraussetzungen #
Die Azure-Storage-Destination (Blob / Data Lake) unterstützt die folgenden Azure-Storage Account-Typen:
- General-purpose V2 (Allgemein, inkl. Azure Data Lake Storage Gen2)
- General-purpose V1 (Allgemein)
- BlockBlobStorage
- BlobStorage
Um Azure-Storage-Destination (Blob / Data Lake) zu verwenden, brauchen Sie eines der oben genannten Konten. Weiterführende Informationen können Sie der offiziellen Microsoft Azure Dokumentation entnehmen.
Verbindung #
Eine Destination hinzufügen #
- Navigieren Sie im Hauptfenster des Designers zu Server > Manage Destinations. Das Fenster “Manage Destination” wird geöffnet.
- Klicken Sie auf [Add], um eine neue Destination hinzufügen. Das Fenster “Destination Details” wird geöffnet.
- Geben Sie einen Namen für die Destination ein.
- Wählen Sie den Destinationstyp aus dem Dropdown-Menü aus.
Destination Details #
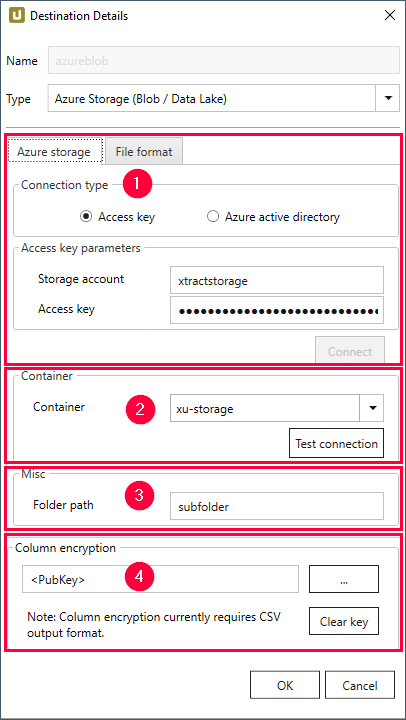
Connection Type - Verbindungstyp (1) #
Der Unterabschnitt Connection bietet zwei verschiedene Methoden zur Authentifizierung und Zugriffssteuerung auf dem Azure Storage:
- Authentifizierung über Access Key (Zugangsschlüssel)
- Authentifizierung über Azure Active Directory (Azure AD)
1. Authentifizierung über Access Key (Zugangsschlüssel)
Diese Authentifizierungsmethode ermöglicht den Zugriff auf das gesamte Azure Storage.
Allgemeine Informationen über diese Authentifizierungsmethode finden Sie in der Microsoft-Dokumentation.
Wählen Sie die [Access key] Checkbox aus, um diesen Verbindungstyp zu verwenden.
Verbindung via Acces Key (Zugangsschlüssel)
Storage account
Geben Sie den Namen des Azure Storage Accounts ein.
Geben Sie nicht die vollständige URL ein.
Access Key
Geben Sie den Azure Storage Zugangsschlüssel ein.
Tipp: Kopieren Sie Name und Access Key (Zugangsschlüssel) des Azure Storage aus dem Azure-Portal.

Connect
Klicken Sie auf [Connect], um eine Verbindung zum Azure Storage herzustellen.
Wenn die Verbindung erfolgreich ist, öffnet sich das Info-Fenster “Connection successful”.
Klicken Sie auf [OK] zum Bestätigen.
2. Authentifizierung über Azure Active Directory
Die Authentifizierung über Azure AD verwendet OAuth 2.0 und Azure AD zur Authentifizierung. Im Vergleich zur Authentifizierung via Access Key erlaubt diese Option eine granularere Zugriffssteuerung. Der Zugriff kann auf das komplette Azure Storage oder auf einzelne Storage-Container autorisiert werden. Allgemeine Informationen über diese Art der Authentifizierung finden Sie in der Microsoft-Dokumentation.
Voraussetzungen
Hinweis: Die Authentifizierung über Azure AD erfordert einen Mandanten (tenant). Die Einrichtung eines Azure AD-Mandanten ist in der Microsoft-Dokumentation beschrieben.
Bevor Sie die Authentifizierung über Azure AD verwenden, führen Sie die folgenden Schritte auf dem Azure-Portal durch:
- Öffnen Sie auf dem Azure-Portal den Service Azure Active Directory.
- Registrieren Sie eine Anwendung auf Ihrem Azure AD-Mandanten, wie beschrieben in der Microsoft-Dokumentation. Registrieren Sie die Anwendung als Public client/native (mobile & desktop).
- Fügen Sie der registrierten Anwendung API-Berechtigungen hinzu, um den Zugriff auf die Azure Storage-Web-API zu gewähren.
Die folgenden Berechtigungen sind erforderlich:
Azure Storage - Delegated permissions - user impersonation,
Microsoft Graph - User.Read.
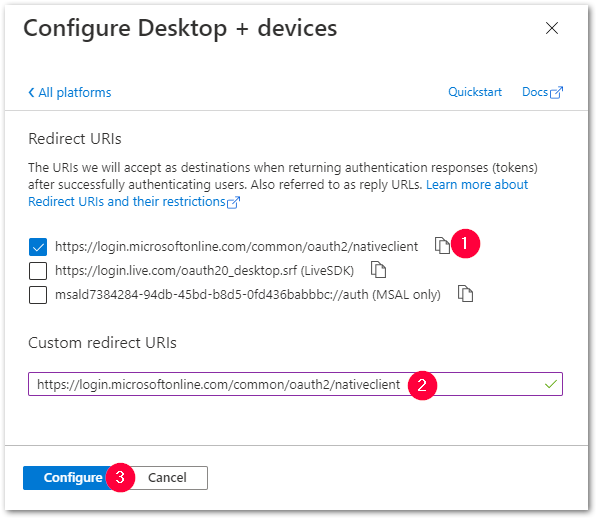
Folgen Sie hierfür den Schritten aus der Microsoft-Dokumentation. - Weisen Sie https://login.microsoftonline.com/common/oauth2/nativeclient als Standard-Redirect-URI zu (1).
Dies kann in der Azure AD-App-Registrierung über Manage > Authentication > Add a platform > Mobile and desktop applications erfolgen.
Kopieren Sie die URL und fügen Sie sie in das Feld Custom redirect URI ein (2) und klicken Sie auf [Configure] (3).
Bestätigen Sie im Bildschirm Authentication mit [Save].
- Öffnen Sie auf dem Azure-Portal Ihr Azure Storage.
- Weisen Sie dem Azure-Storage Zugriffsrechte zu. Folgen Sie hierfür den Schritten beschrieben in der Microsoft-Dokumentation.
Die erforderliche RBAC-Rolle ist Storage Blob Data Contributor.
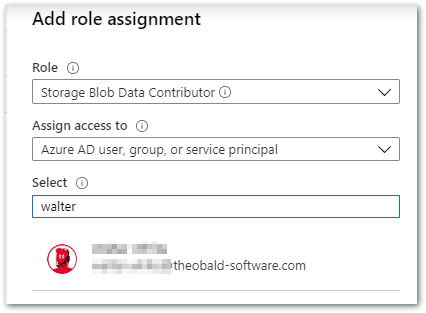
Tipp: Zugriffsrechte können auf Azure Storage- oder Container-Ebene gewährt werden.
Verbindung über Azure Active Directory
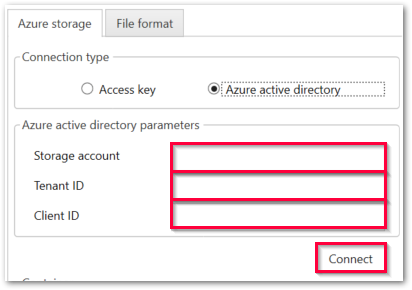
Storage account
Geben Sie den Namen des Azure Storage Accounts ein.
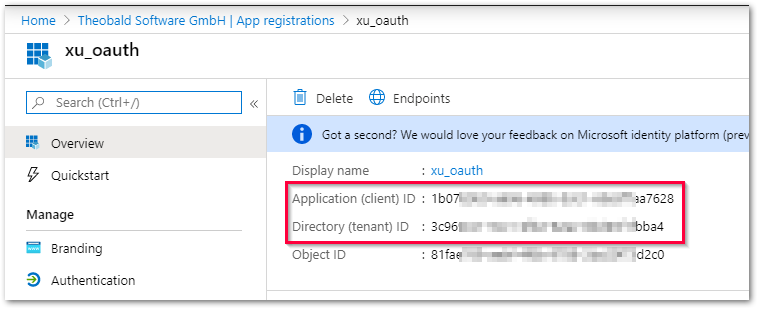
Tenant ID
Geben Sie die ID des Azure AD-Mandanten ein.
Client ID
Geben Sie die Client ID der registrierten Anwendung ein.
Tipp: Kopieren Sie die Tenant-ID und Client-ID aus dem Azure-Portal.
Connect
Verbindung mit dem Azure Storage aufbauen:
- Klicken Sie auf [Connect]. Ein Browser-Fenster wird geöffnet.
- Melden Sie sich mit Ihren Azure AD-Zugangsdaten an.
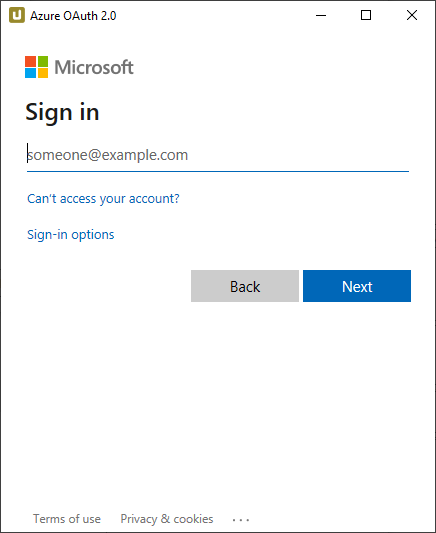
- Das Fenster “Permissions requested” (Angeforderte Berechtigungen) listet die angeforderten Berechtigungen auf (siehe Voraussetzungen oben). Klicken Sie auf [Accept].
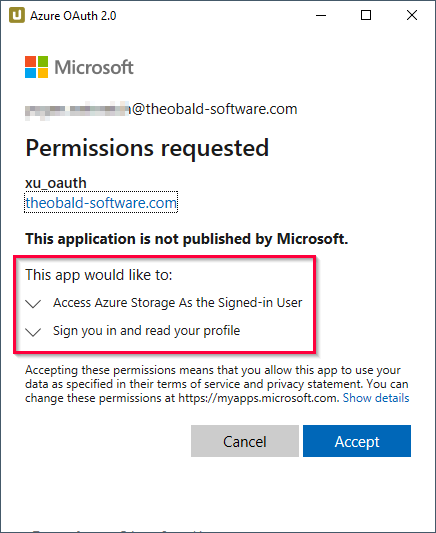
- Wenn die Verbindung erfolgreich ist, wird das Info-Fenster “Connection successful” geöffnet. Klicken Sie auf [OK] zum Bestätigen.
Container (2) #
Dieser Unterabschnitt wird aktiviert, nachdem eine Verbindung zum Azure Storage (Storage Account) erfolgreich hergestellt wurde.
Container
Bei der Authentifizierung über Access Key (Zugangsschlüssel) kann ein Blob-Container aus dem Drop-down-Menü ausgewählt werden.
Bei der Authentifizierung über Azure AD geben Sie den Namen eines Blob Containers manuell ein.
Test connection
(Verbindung zum Container testen)
Klicken Sie auf [Test Connection], um zu überprüfen ob auf den Storage-Container zugegriffen werden kann.
Bei einer erfolgreichen Verbindung wird das Info-Fenster “Connection to container <Container-Name> successful” geöffnet.
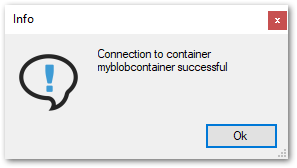 Klicken Sie auf [OK] zum Bestätigen.
Klicken Sie auf [OK] zum Bestätigen.
Die Destination Azure Storage (Blob / Data Lake) kann nun verwendet werden.
Misc (3) #
Hinweis: Die Einstellungen in Misc können nur in Kombination mit einem Blob Container verwendet werden.
Folder path
Option zum Erstellen eines Verzeichnisses innerhalb des Containers zum Abspeichern von Dateien, siehe auch: Einstellungen > Folder Path.
Wenn die Extraktionsdaten in einen Ordner innerhalb eines Azure-Blob-Containers geschrieben werden sollen, geben Sie hier einen Ordnernamen ohne Schrägstriche ein: [Ordner]
Unterordner werden ebenfalls unterstützt und können wie folgt eingegeben werden: [ordner]/[unterordner_1]/[unterordner_2]/…
Skript-Ausdrücke als dynamische Ordnerpfade
Skript-Ausdrücke können für die Generierung eines dynamischen Ordnerpfads verwendet werden. Dadurch kann ein Ordnerpfad generiert werden, der sich aus den Eigenschaften einer Extraktion zusammensetzt, z.B. Extraktionsname, SAP-Quellobjekt. Unterstützt werden Skript-Ausdrücke, die auf .NET basieren, sowie folgende XU-spezifische Skript-Ausdrücke:
| Eingabe | Beschreibung |
|---|---|
#{Source.Name}# |
Name der SAP Quelle. |
#{Extraction.ExtractionName}# |
Name der Extraktion. Wenn die Extraktion Teil einer Extraktionsgruppe ist, geben Sie den Namen der Extraktionsgruppe vor dem Namen der Extraktion ein. Trennen Sie Gruppen mit ‘,’, z.B., Tables,KNA1, S4HANA,Tables,KNA1. |
#{Extraction.Type}# |
Extraktionstyp (Table, ODP, DeltaQ, etc.). |
#{Extraction.SapObjectName}# |
Name des SAP Objekts, von dem die Extraktion Daten extrahiert. |
#{Extraction.Timestamp}# |
Zeitstempel der Extraktion. |
#{Extraction.SapObjectName.TrimStart("/".ToCharArray())}# |
Entfernt einen führenden Schrägstrich, z.B. wird aus /BIO/TMATERIAL dann BIO/TMATERIAL, damit kein leeres Verzeichnis angelegt wird. |
#{Extraction.SapObjectName.Replace('/', '_')}# |
Entfernt alle Schrägstriche eines SAP Objekts, z.B. wird aus /BIO/TMATERIAL dann _BIO_TMATERIAL. Dadurch wird verhindert, dass die Schrägstriche innerhalb des Namens des SAP Objekts, nicht als Verzeichnistrenner interpretiert werden. |
#{Extraction.Context}# |
Nur für ODP Extraktionen: Kontext des ODP Objekts (SAPI, ABAP_CDS, etc.). |
#{Extraction.Fields["[NameSelectionFields]"].Selections[0].Value}# |
Nur für ODP Extraktionen: Eingabewert einer definierten Selektion / eines Filter. |
#{Odp.UpdateMode}# |
Nur für ODP Extraktionen: Load-Verfahren (Delta, Full, Repeat) der Extraktion. |
#{TableExtraction.WhereClause}# |
Nur für Table Extraktionen: WHERE-Bedingung der Extraktion. |
#{Extraction.Fields["[0D_NW_CODE]"].Selections[0].Value}# |
Nur für BWCube Extraktionen (MDX Modus): Eingabewert einer definierten Selektion. |
#{Extraction.Fields["[0D_NW_CHANN]"].RangeSelections[0].LowerValue}# |
Nur für BWCube Extraktionen (MDX Modus): Niedriger Eingabewert eines definierten Selektionsbereichs. |
#{Extraction.Fields["[0D_NW_CHANN]"].RangeSelections[0].UpperValue}# |
Nur für BWCube Extraktionen (MDX Modus): Hoher Eingabewert eines definierten Selektionsbereichs. |
#{Extraction.Fields["0D_NW_CODE"].Selections[0].Value}# |
Nur für BWCube Extraktionen (BICS Modus): Eingabewert einer definierten Selektion. |
#{Extraction.Fields["0D_NW_CHANN"].RangeSelections[0].LowerValue}# |
Nur für BWCube Extraktionen (BICS Modus): Niedriger Eingabewert eines definierten Selektionsbereichs. |
#{Extraction.Fields["0D_NW_CHANN"].RangeSelections[0].UpperValue}# |
Nur für BWCube Extraktionen (BICS Modus): Hoher Eingabewert eines definierten Selektionsbereichs. |
Column Encryption (4) #
Allgemeines
Sie können Daten sowohl verschlüsselt als auch unverschlüsselt speichern. Die “Column Encryption” (Spalten-Verschlüsselung) ermöglicht Ihnen eine Verschlüsselung der Spalten bevor die extrahierten Daten in die Destination hochgeladen werden. Dadurch kann sichergestellt werden, dass sensible Informationen geschützt sind.
Diese Funktion unterstützt außerdem wahlfreien Zugriff, d.h. dass Daten von jedem beliebigen Startpunkt aus entschlüsselt werden können. Da wahlfreier Zugriff einen erheblichen Overhead verursacht, wird empfohlen die Spalten-Verschlüsselung nicht auf den gesamten Datensatz anzuwenden.
Weiteres Vorgehen
Hinweis: Der Benutzer muss einen öffentlichem RSA Schlüssel zur Verfügung stellen.
-
Wählen Sie die zu verschlüsselnden Spalten unter Extraction settings > General settings > Encryption aus.
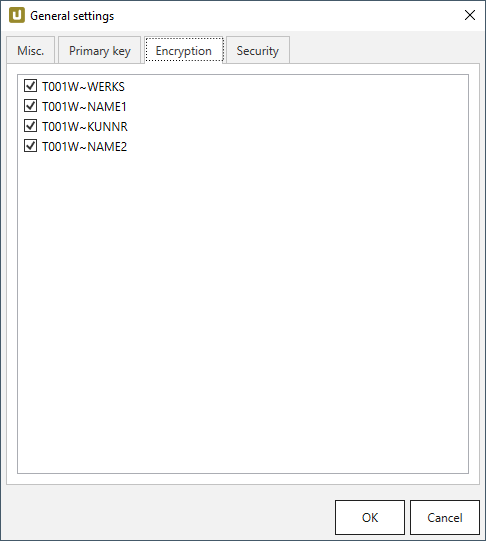
-
Stellen Sie sicher, dass die Enable column level encryption Checkbox unter Extraction settings > General settings > Misc. ausgewählt ist.
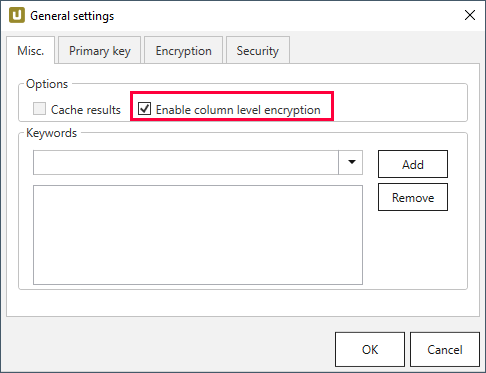
-
Klicken Sie unter Destination Details > Column Encryption auf […], um den öffentlichen Schlüssel als .xml-Datei zu importieren.
-
Führen Sie die Extraktion aus.
-
Warten Sie bis XtractUniversal die verschlüsselten Daten und die “metadata.json” Datei auf die Destination hochgeladen hat.
-
Triggern Sie manuell oder automatisch Ihre Entschlüsselungsroutine.
Entschlüsselung
Die Entschlüsselung ist abhängig von der Destination. Beispiele für eine Implementierung mit Azure Storage, AWS S3 und lokalen CVS Dateien finden Sie in GitHub. Die Beispiele beinhalten sowohl Kryptografie als auch ein Interface, um “metadata.json” und CSV Daten zu lesen. Der kryptografische Aspekt ist Open Source, das Interface nicht.
Technische Informationen
Die Verschlüsselung ist als Hybridverschlüsselung implementiert.
Das bedeutet, dass ein zufälliger AES Session Key (Sitzungsschlüssel) generiert wird sobald eine Extraktion ausgeführt wird.
Die Daten werden dann über den AES-GCM Algorithmus in Kombination mit dem Session Key verschlüsselt.
Die Implementierung verwendet die empfohlene Länge von 96 bits für den Initialisierungsvektor (IV).
Um den wahlfreien Datenzugriff zu garantieren, erhält jede Zelle seinen eigenen IV/nonce und einen Message Authentication Code (MAC).
Der MAC ist ein Authentifizierungstoken in GCM.
Im daraus resultierenden Datenset sind die Zellen wie folgt verschlüsselt:
IV|ciphertext|MAC
mit IV als 7-Bit Integer. Der Session Key wird daraufhin mit dem öffentlichen RSA Schlüssel des Benutzers verschlüsselt und zusammen mit einer Liste verschlüsselter Spalten und Formatinformation als “metadata.json” Datei auf die Destination hochgeladen.
File Format #
File type
Wählen Sie das gewünschte Dateiformat aus dem Dropdown Menü.
Die Formate Parquet und CSV sind verfügbar.
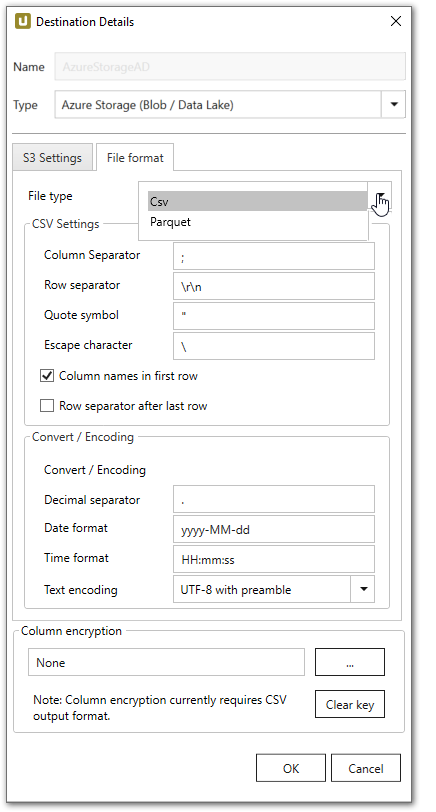
CVS Settings
Die Einstellungen für den Dateityp CSV entsprechen den allgemeinen Flat File CSV Einstellungen.
Parquet Settings
Die folgenden Kompatibilitätsmodi sind verfügbar:
- Pure
- Spark
- BigQuery
Spark unterstützt nicht die im Pure-Mode verwendeten Datentypen, daher müssen andere Datentypen verwendet werden. Sonderzeichen (z.B. ~ ) können in Spaltennamen verwendet werden, wenn die Option Allow special characters in column name activiert ist.
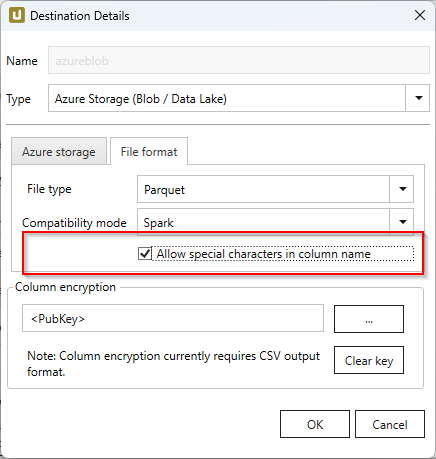
| SAP | Pure / BigQuery | Spark |
|---|---|---|
| INT1 | UINT_8 | INT16 |
| TIMS | TIME_MILLIS | UTF8 |
Retry- und Rollback-Funktion #
Die Retry- und Rollback-Funktionen sind eingebaute Wiederholungsmechanismen der Azure Storage Destination, die automatisch aktiviert sind.
Die Retry-Funktion verhindert, dass Extraktionen fehlschlagen wenn kurzzeitige Verbindungsunterbrechungen zu Azure auftreten. Die Implementierung der Retry- und Rollback-Funktion entspricht den Microsoft Richtlinien. Die Logik der Funktion basiert auf dem WebExceptionStatus.
Sollte eine Ausnahme (Exception) ausgelöst werden, verfolgt Xtract Universal eine exponentielle Strategie der Wiederholversuche. Das bedeutet, dass 7 Verbindungsversuche gestartet werden in einem Zeitraum von 140 Sekunden. Sollte in diesem Zeitraum keine Verbindung zustande kommen, wird die Extraktion abgebrochen.
Die Rollback-Funktion deckt Szenarien ab, bei denen eine Extraktion nicht wegen eines Verbindungsfehlers zu Azure fehlschlägt, sondern z.B. wegen eines Verbindungsfehlers zu SAP. In solchen Fällen versucht Xtract Universal alle Dateien aus dem Azure Storage zu entfernen, die im Laufe der Extraktion erstellt wurden.
Einstellungen #
Destination Settings öffnen #
- Eine bestehende Extraktion anlegen oder auswählen, siehe Erste Schritte mit Xtract Universal.
- Klicken Sie auf [Destination]. Das Fenster “Destination Settings” wird geöffnet.
Die folgenden Einstellungen können für die Destination definiert werden.
Destination Settings - Destinationseinstellungen #
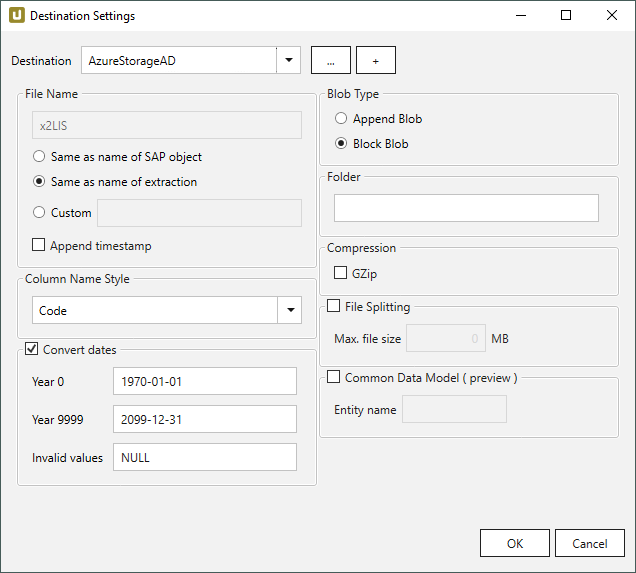
File Name #
File Name bestimmt den Namen der Zieltabelle. Sie haben die folgenden Optionen:
- Same as name of SAP object: Name des SAP-Objekts übernehmen
- Same as name of extraction: Name der Extraktion übernehmen
- Custom: Hier können Sie einen eigenen Namen definieren
- Append timestamp: fügt den Zeitstempel im UTC-Format (_YYYY_MM_DD_hh_mm_ss_fff) dem Dateinamen der Extraktion hinzu.
Hinweis: Wenn der Name eines Objekts nicht mit einem Buchstaben beginnt, wird ‘x’ als Präfix ergänzt, z.B. wird das Objekt _namespace_tabname.csv zu x_namespace_tabname.csv, wenn es auf die Destination hochgeladen wird.
Damit wird die Kompatibilität zu Azure Data Factory, Hadoop und Spark sichergestellt, die mit Buchstaben beginnende Objektnamen voraussetzen oder die nicht alphabetischen Zeichen besondere Bedeutungen zuweisen.
Skript-Ausdrücke als dynamische Dateinamen
Skript-Ausdrücke können für die Generierung eines dynamischen Dateinamens verwendet werden. Dadurch kann ein Name generiert werden, der sich aus den Eigenschaften einer Extraktion zusammensetzt, z.B. Extraktionsname, SAP-Quellobjekt. Unterstützt werden Skript-Ausdrücke, die auf .NET basieren, sowie folgende XU-spezifische Skript-Ausdrücke:
| Eingabe | Beschreibung |
|---|---|
#{Source.Name}# |
Name der SAP Quelle. |
#{Extraction.ExtractionName}# |
Name der Extraktion. Wenn die Extraktion Teil einer Extraktionsgruppe ist, geben Sie den Namen der Extraktionsgruppe vor dem Namen der Extraktion ein. Trennen Sie Gruppen mit ‘,’, z.B., Tables,KNA1, S4HANA,Tables,KNA1. |
#{Extraction.Type}# |
Extraktionstyp (Table, ODP, DeltaQ, etc.). |
#{Extraction.SapObjectName}# |
Name des SAP Objekts, von dem die Extraktion Daten extrahiert. |
#{Extraction.Timestamp}# |
Zeitstempel der Extraktion. |
#{Extraction.SapObjectName.TrimStart("/".ToCharArray())}# |
Entfernt einen führenden Schrägstrich, z.B. wird aus /BIO/TMATERIAL dann BIO/TMATERIAL, damit kein leeres Verzeichnis angelegt wird. |
#{Extraction.SapObjectName.Replace('/', '_')}# |
Entfernt alle Schrägstriche eines SAP Objekts, z.B. wird aus /BIO/TMATERIAL dann _BIO_TMATERIAL. Dadurch wird verhindert, dass die Schrägstriche innerhalb des Namens des SAP Objekts, nicht als Verzeichnistrenner interpretiert werden. |
#{Extraction.Context}# |
Nur für ODP Extraktionen: Kontext des ODP Objekts (SAPI, ABAP_CDS, etc.). |
#{Extraction.Fields["[NameSelectionFiels]"].Selections[0].Value}# |
Nur für ODP Extraktionen: Eingabewert einer definierten Selektion / eines Filter. |
#{Odp.UpdateMode}# |
Nur für ODP Extraktionen: Load-Verfahren (Delta, Full, Repeat) der Extraktion. |
#{TableExtraction.WhereClause}# |
Nur für Table Extraktionen: WHERE-Bedingung der Extraktion. |
Column Name Style #
Definiert den Spaltennamen. Folgende Optionen sind verfügbar:
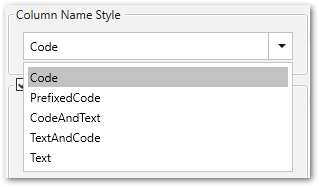
- Code: Der technische Spaltenname aus SAP wird als Spaltenname verwendet, z.B. MAKTX
- PrefixedCode: Der technische Name der Tabelle wird mit dem Tilde-Zeichen und dem entsprechenden Spaltennamen verbunden, z. B. MAKT~MAKTX.
- CodeAndText: Der technische Name und die Beschreibung der Spalte aus SAP mit einem Unterstrich verbunden werden als Spaltennamen verwendet, z.B. MAKTX_Material Description (Short Text).
- TextAndCode: Die Beschreibung und der technische Name der Spalte SAP mit einem Unterstrich verbunden werden als Spaltennamen verwendet, z.B. Material Description (Short Text)_MAKTX.
- Text: Die Beschreibung aus SAP wird als Spaltenname verwendet, z.B. Material Description (Short Text).
Date conversion #
Convert date strings
Konvertiert die Zeichenabfolge des SAP-Datums (YYYYMMDD, z.B. 19900101) zu einem formatierten Datum (YYYY-MM-DD, z.B. 1990-01-01). Im Datenziel hat das SAP-Datum keinen String-Datentyp sondern einen echten Datumstyp.
Convert invalid dates to
Falls ein SAP-Datum nicht in ein gültiges Datumsformat konvertiert werden kann, wird das ungültige Datum zu dem eingegebenen Wert konvertiert. NULL wird als Wert unterstützt.
Bei der Konvertierung eines ungültigen SAP-Datums werden zuerst die beiden Sonderfälle 00000000 und 9999XXXX überprüft.
Convert 00000000 to
Konvertiert das SAP-Datum 00000000 zu dem eingegebenen Wert.
Convert 9999XXXX to
Konvertiert das SAP-Datum 9999XXXX zu dem eingegebenen Wert.
Blob Type #
Append Blob
Erstelt ein Append Blob.
Block Blob
Erstellt ein Block Blob.
Note: Für beide Dateitypen wird beim Hochladen nach Azure-Storage automatisch ein MD5-Hash erstellt.
Folder #
Wenn die Extraktionsdaten in einen Ordner innerhalb eines Azure-Blob-Containers geschrieben werden sollen, geben Sie hier einen Ordnernamen ohne Schrägstriche ein: [Ordner]
Unterordner werden ebenfalls unterstützt und können wie folgt eingegeben werden: [ordner]/[unterordner_1]/[unterordner_2]/…
Skript-Ausdrücke als dynamische Ordnerpfade
Skript-Ausdrücke können für die Generierung eines dynamischen Ordnerpfads verwendet werden. Dadurch kann ein Ordnerpfad generiert werden, der sich aus den Eigenschaften einer Extraktion zusammensetzt, z.B. Extraktionsname, SAP-Quellobjekt. Unterstützt werden Skript-Ausdrücke, die auf .NET basieren, sowie folgende XU-spezifische Skript-Ausdrücke:
| Eingabe | Beschreibung |
|---|---|
#{Source.Name}# |
Name der SAP Quelle. |
#{Extraction.ExtractionName}# |
Name der Extraktion. Wenn die Extraktion Teil einer Extraktionsgruppe ist, geben Sie den Namen der Extraktionsgruppe vor dem Namen der Extraktion ein. Trennen Sie Gruppen mit ‘,’, z.B., Tables,KNA1, S4HANA,Tables,KNA1. |
#{Extraction.Type}# |
Extraktionstyp (Table, ODP, DeltaQ, etc.). |
#{Extraction.SapObjectName}# |
Name des SAP Objekts, von dem die Extraktion Daten extrahiert. |
#{Extraction.Timestamp}# |
Zeitstempel der Extraktion. |
#{Extraction.SapObjectName.TrimStart("/".ToCharArray())}# |
Entfernt einen führenden Schrägstrich, z.B. wird aus /BIO/TMATERIAL dann BIO/TMATERIAL, damit kein leeres Verzeichnis angelegt wird. |
#{Extraction.SapObjectName.Replace('/', '_')}# |
Entfernt alle Schrägstriche eines SAP Objekts, z.B. wird aus /BIO/TMATERIAL dann _BIO_TMATERIAL. Dadurch wird verhindert, dass die Schrägstriche innerhalb des Namens des SAP Objekts, nicht als Verzeichnistrenner interpretiert werden. |
#{Extraction.Context}# |
Nur für ODP Extraktionen: Kontext des ODP Objekts (SAPI, ABAP_CDS, etc.). |
#{Extraction.Fields["[NameSelectionFields]"].Selections[0].Value}# |
Nur für ODP Extraktionen: Eingabewert einer definierten Selektion / eines Filter. |
#{Odp.UpdateMode}# |
Nur für ODP Extraktionen: Load-Verfahren (Delta, Full, Repeat) der Extraktion. |
#{TableExtraction.WhereClause}# |
Nur für Table Extraktionen: WHERE-Bedingung der Extraktion. |
#{Extraction.Fields["[0D_NW_CODE]"].Selections[0].Value}# |
Nur für BWCube Extraktionen (MDX Modus): Eingabewert einer definierten Selektion. |
#{Extraction.Fields["[0D_NW_CHANN]"].RangeSelections[0].LowerValue}# |
Nur für BWCube Extraktionen (MDX Modus): Niedriger Eingabewert eines definierten Selektionsbereichs. |
#{Extraction.Fields["[0D_NW_CHANN]"].RangeSelections[0].UpperValue}# |
Nur für BWCube Extraktionen (MDX Modus): Hoher Eingabewert eines definierten Selektionsbereichs. |
#{Extraction.Fields["0D_NW_CODE"].Selections[0].Value}# |
Nur für BWCube Extraktionen (BICS Modus): Eingabewert einer definierten Selektion. |
#{Extraction.Fields["0D_NW_CHANN"].RangeSelections[0].LowerValue}# |
Nur für BWCube Extraktionen (BICS Modus): Niedriger Eingabewert eines definierten Selektionsbereichs. |
#{Extraction.Fields["0D_NW_CHANN"].RangeSelections[0].UpperValue}# |
Nur für BWCube Extraktionen (BICS Modus): Hoher Eingabewert eines definierten Selektionsbereichs. |
Common Data Model #
Wenn die Option Common Data Model aktiv ist, wird eine Common DATA Model JSON Datei erstellt und zusammen mit den extrahierten Daten in die Destination geschrieben.
Die CDM Datei kann verwendet werden, um Datentransformationen in Azure zu automatisieren.
Für mehr Informationen zu Common Data Models, siehe Microsoft Dokumentation: Common Data Model.
Entity name
Geben Sie einen Namen für die generierte .cdm.json Datei ein.
Hinweis: Diese Funktion befindet sich noch im Preview-Modus.
Compression #
None
Die Daten werden unkomprimiert übertragen und als csv-Datei abgelegt.
gzip
Die Daten werden komprimiert übertragen und als gz-Datei abgelegt.
Hinweis: Diese Option ist nur für das csv-Dateiformat verfügbar, siehe Verbindung: File Format.
File Splitting #
File Splitting
Schreibt die Extraktionsdaten einer einzelnen Extraktion in mehrere Dateien im die Cloud. Dabei wird an jeden Dateinamen _part[nnn] angehägt.
Max. file size
Geben Sie die Maximalgröße der Dateien ein, die hochgeladen werden sollen.
Note: Die Option Max. file size wird nicht von gzip-Dateien unterstützt. Die Größe von durch gzip-Verfahren komprimierten Dateien kann nicht im Voraus bestimmt werden.